NVIDIA에서 발표한 논문으로, CVPR 2025에서 포스터 세션으로 소개되었습니다. 기존 VLM구조를 더 효율적으로 개량한 NVILA 모델을 소개합니다.
https://nvlabs.github.io/VILA/
NVILA: Efficient Frontiers of Visual Language Models
NVILA's core design concept In this paper, we introduce NVILA, a family of open VLMs designed to optimize both efficiency and accuracy. Building on VILA, we improve its model architecture by first scaling up the spatial and temporal resolution, followed by
nvlabs.github.io
1. Introduction

그동안 VLMs은 다양한 분야에 적용되도록 활발히 연구되어 왔습니다. 하지만 효율성의 측면에서 VLMs은 아직 해결해야 할 문제들이 남아 있습니다.
- Time-consuming. 한 번 학습시키는데 많은 시간이 필요합니다. 예시로 7B 크기의 SoTA VLM을 학습시키는데 400 GPU day가 소요됩니다.
- Memory-intensive. VLM을 특정 분야(의학 분야 등)에 맞게 사용하기 위해서는 추가적인 학습이 필요하는데, 이 finetuning 과정에서 많은 메모리를 소모합니다.
- Resource-constrained. VLM이 특정 말단에서 작동할 때는 그만큼 계산 환경에 제약이 생길 수 밖에 없습니다.
이러한 문제를 해결하기 위해 본 연구는 효율성과 정확성을 모두 향상시킨 모델 NVILA를 고안해냈습니다. NVILA는 데이터 scaling up을 통해 시공간 해상도를 높이고 visual token은 압축하는 "scale-then-compress" 기법을 활용하여 세부사항은 유지하면서도(scaling) 계산 효율은 증가시키는(compression)데에 성공했습니다.
실제로 성능을 시험했을 때, NVILA는 training cost는 1.9-5.1✕, prefilling latency는 1.6-2.2✕, 그리고 decoding latency는 1.2-2.8✕의 성능 향상을 기록했다고 합니다.


2. Approach
NVLIA는 또한 모델 생명주기 전체(학습 - fintuning)에 걸져 효율성을 향상시켰다고 합니다.
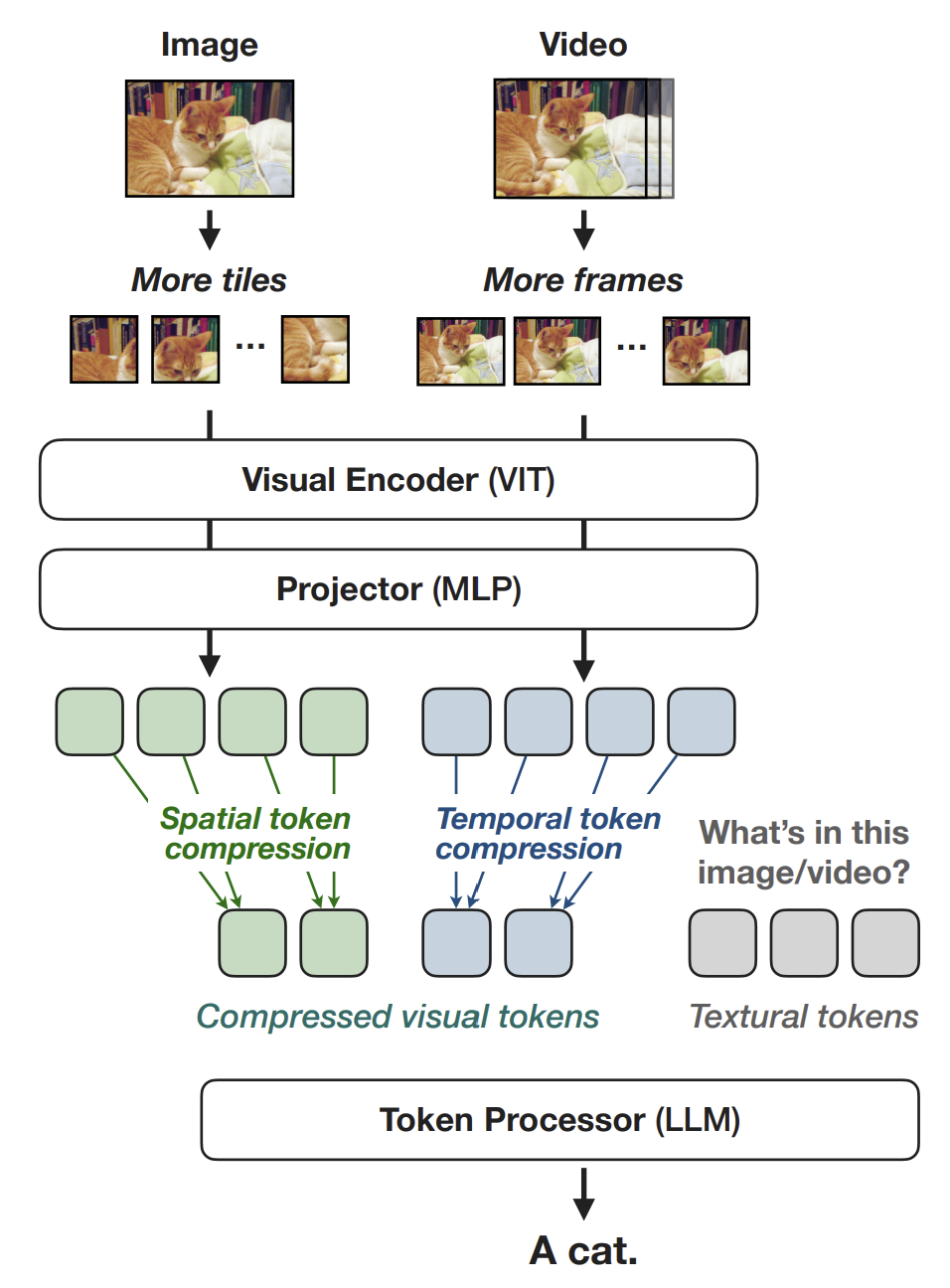
2.1. Efficient Model Architecture
NVILA는 VILA 모델을 기반으로 하였습니다. VILA는 아래 세 가지 요소로 구성된 auto-regressive 모델입니다.
| 역할 | NVILA가 사용한 모델 | |
| Visual encoder | 입력값(이미지, 영상)에서 visual feature를 추출 | SigLIP |
| Projector | visual feature embedding을 token으로 전환 | two-layer MLP |
| Token processor | 변환한 token과 텍스트 입력값을 language token(응답)으로 전환 | Qwen2 |
원본 VILA는 시공간적으로 제한된 크기의 조건을 가지고 있습니다. VILA는 입력값의 크기나 비율과 관계없이 448 * 448의 크기로 변환하는데, 이 과정에서 상당한 정보의 손실이 발생하게 됩니다. 때문에 NVILA는 scale-then-compress를 통해 이 문제점을 극복하고자 합니다.
2.1.1. Spatial "Scale-Then-Compress"
Vision encoder에서 이미지 해상도를 높이는 것(scaling)은 간단합니다. 하지만 굳이 높은 해상도가 필요하지 않은 작은 이미지에 대해서도 scaling을 적용하면 상당히 비효율적일 수도 있습니다. 이를 위해 본 연구는 $S^2$(Scaling on Scales)를 사용하였습니다. $S^2$는 입력 이미지를 여러 크기로 경우를 나누고(e.g. $448^2, 896^2$ 등), 각 크기별로 tiling 기법을 적용(e.g. 각 이미지를 448 * 448 크기의 격자로 분할)합니다. 각각의 tile에 대해 visual encdoer 계산을 수행하면, 그 visual feature 결과값을 다시 하나로 합쳐 전체 visual feature 결과값을 반환합니다. 마지막으로 각 경우로 나뉘 서로 다른 이미지 크기에 대한 visual feature 값을 보간을 통해 하나로 합쳐 최종 결과값을 만듭니다.
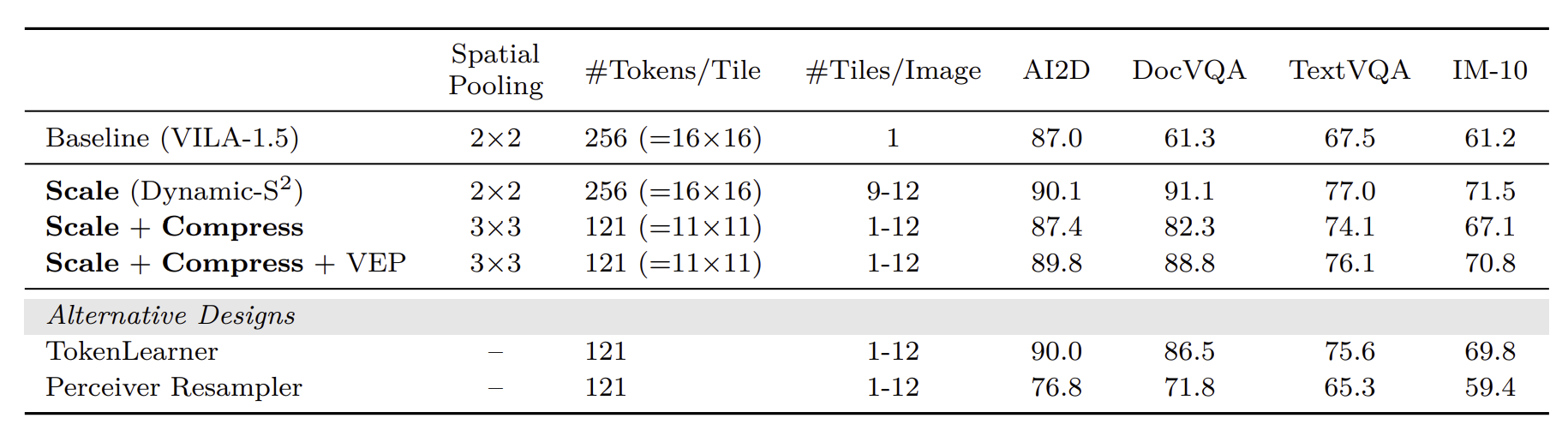
$S^2$는 전체 이미지의 종횡비와 관계 없이 무조건 정사각형으로 tiling하기 때문에 이미지가 왜곡될 수도 있습니다. 이를 방지하기 위해 InternVL 모델의 아이디어를 차용한 $Dynamic-S^2$를 사용합니다. 이는 가장 큰 이미지를 정사각형 tile(e.g. 448 * 448)들로 정확히 나눌 수 있는 가장 비슷한 크기로 축소시킵니다. Visual feature들을 보간으로 합치는 과정은 동일하게 수행합니다. $Dynamic-S^2$를 적용했을 때, 모델 정확도가 30% 향상되었다고합니다([표 1]).
원본 VILA의 경우 spatial token을 압축할 때(compressing) 간단한 2 * 2 spatial-to-channel(STC) reshape을 사용하였습니다. 하지만 tile의 개수를 줄이고 압축 정도를 3 * 3으로 올려보니 그 성능이 저하되었다고 합니다. 압축 정도를 올릴수록 그 만큼 학습시키기가 어려워진다는 뜻입니다. 이를 해결하기 위해 본 연구는 visual encoder를 추가적으로 학습시키는 pre-train stage를 만들었습니다. 그 결과 학습 및 추론 과정에서 2.4✕의 speedup이 있었다고 합니다.
참고로 spatial token compression에서는 이것 말고도 다양한 방법이 있다고 합니다. 하지만 모두 이 간단한 STC 모델보다는 뛰어난 성능을 보이지 못했는데, 이에 대해서는 본 연구에서 자세히 다루지 않았습니다.
2.1.2. Temporal "Scale-Then-Compress"
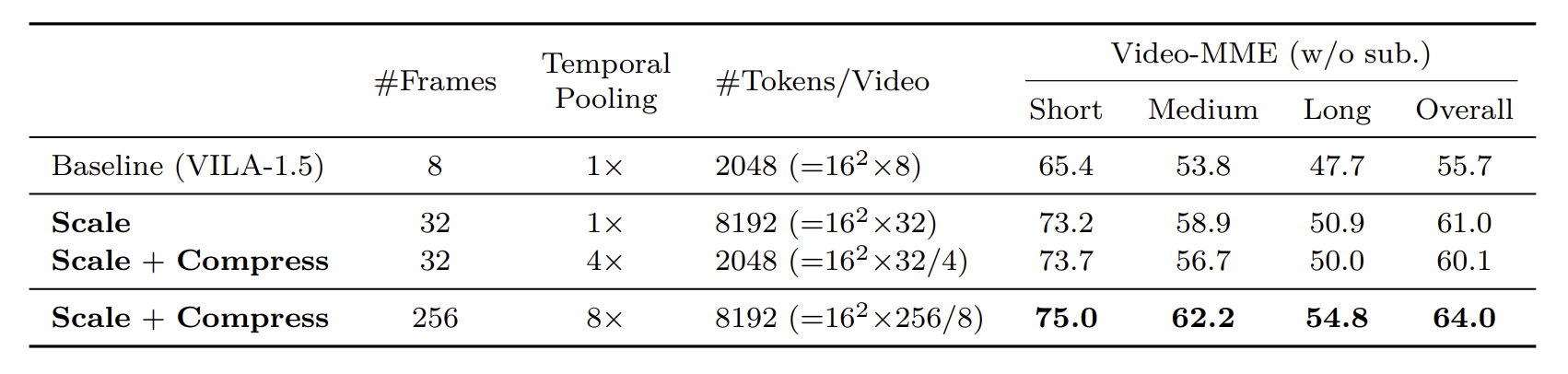
Temporal scaling은 단순히 더 많은 프레임을 선택함으로서 이루어집니다. 이 과정에서 모델이 더 많은 프레임을 처리하도록 video-supervised finetuning(SFT)를 사용하였습니다. 프레임의 수를 8 에서 32만큼 늘려 실험한 결과, 정확도(Video-MME)가 5% 증가했다고 합니다. 하지만 그 만큼 visual token의 수도 4배 증가하였습니다.
Temporal compression은 temporal averaging 기법을 사용하였습니다. 영상에의 temporal consistency를 반영하기 위해, 영상을 각 부분으로 그룹지어 각 그룹별로 visual token을 pooling을 진행하는 방식입니다. 이를 이용해 visual token을 4배 압축해도 정확도는 크게 하락하지 않음을 확인했습니다.
2.2. Efficient Training
2.2.1. Dataset Pruning
기존의 연구들은 뛰어난 성능을 위해 고품질의 SFT 데이터셋을 만드는데 집중했고, 실제로 높은 벤치마킹 점수를 달성하기도 했습니다. 하지만 그 데이터셋의 모든 데이터들이 같은 중요도를 가지는 것도 아니고, 또 데이터셋이 커질수록 불필요하게 중복되는 데이터도 생기기 마련입니다. NVILA는 "scale-then-compress"를 주요 철학으로 잡고있기 때문에, 데이터셋에 대해서도 이 scaling과 compression을 적용하였습니다. 그런데 compression의 경우, 데이터셋에서 중요한 데이터만을 선별하는 것은 상당히 까다롭습니다. 이때까지 시각적 데이터나 텍스트 데이터 입력값에 대한 연구는 있었지만, 이 둘을 동시에 다루는 VLM 학습에 대한 연구는 적기도 합니다.
본 연구는 knowledge distillation* 개념을 바탕으로 DeltaLoss를 사용해 데이터셋에 점수를 부여하고, 학습 데이터를 압축시키기로 했습니다.
* Knowledge distillation : 큰 모델(large model)의 지식을 작은 모델(small model)에 전이시켜 모델을 경량화하는 학습 기법
$ D' = \bigcup_{i=1}^{K} \text{top-}K \left\{ \log \frac{p_{\text{large}}(x)}{p_{\text{small}}(x)} \,\middle|\, x \in D_i \right\} \quad (1) $
- $D'$ : 압축된 데이터셋
- $D_i$ : 전체 데이터셋의 i 번째 subset
- $p_{large}(x)$ : large model의 answer token 예측 확률
- $p_{small}(x)$ : small model의 answer token 예측 확률
골자는, 기존 데이터셋에서 너무 쉽거나 너무 어려운 예시를 골라낸다는 것입니다. 큰 모델이 정확하게 학습되었다는 전제 하에 각 경우를 살펴보면 아래와 같으므로, $D'$의 점수를 타당하게 사용할 수 있습니다.
| $log(\cdot)$항의 값은 | 큰 모델이 정확하게 예측 | 큰 모델이 틀리게 예측 |
| 작은 모델이 정확하게 예측 | 0에 수렴 => 자명한 문제여서 별로 필요 없음 |
음수 => 이상한 문제여서 제외시켜야 함 |
| 작은 모델이 틀리게 예측 | 양수 => 작은 모델이 학습할 만한 test case |
0에 수렴 => 어려운 문제여서 별로 필요 없음 |

정확한 성능 평가를 위해 DeltaLoss 기법을 무작위로 선택된 데이터셋(random pruning), 그리고 k-means clustering 적용 후 각 centroid에서 균일하게 추출한 데이터셋(cluster pruning)과 비교하였습니다. DeltaLoss 데이터셋은 압축 정도를 10%, 30%, 50%로 바꿔가며 평가했습니다.
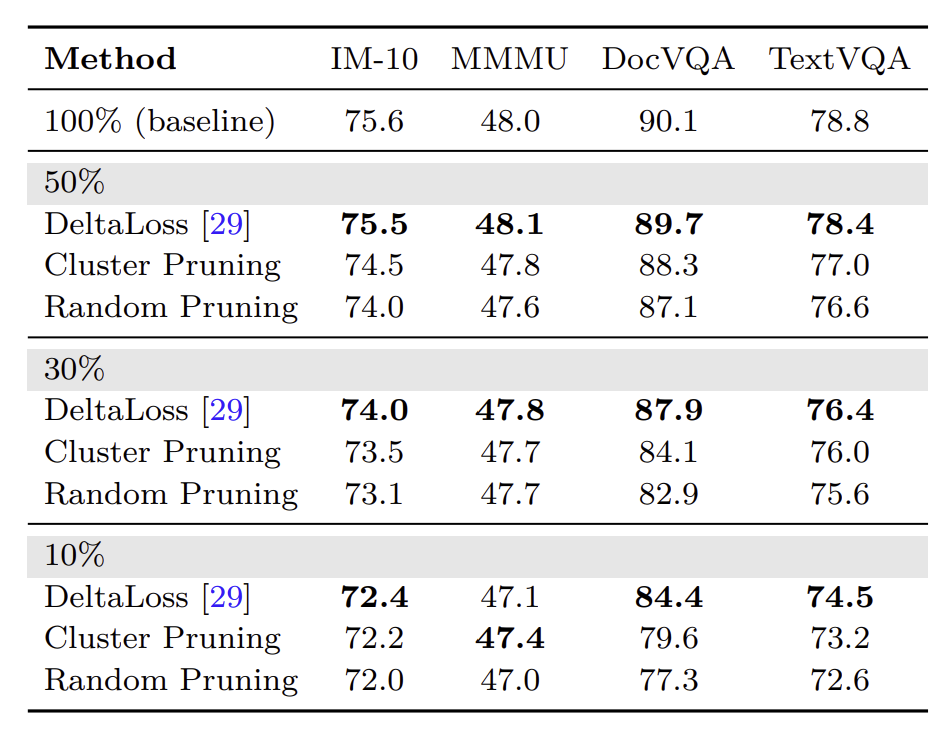
본 연구는 이러한 사실을 바탕으로 pixmo 데이터셋을 DeltaLoss를 통해 압축하여 NVILA 데이터셋에 추가하였습니다. 압축 없이 바로 추가하였을 때는 실제로 벤치마크에서 성능 하락이 있었다고 합니다.
2.2.2. FP8 Training
원래 FP16dhk BF16이 모델 학습에서 사용되는 대표적인 정밀도 수치였으나 최근 H100과 Blackwell 등의 지원으로 FP8 정밀도가 새로운 포맷으로 떠올랐습니다. FP8는 대규모 연산과 메모리의 효율성으로 유망한 표준으로 떠오르고 있습니다.
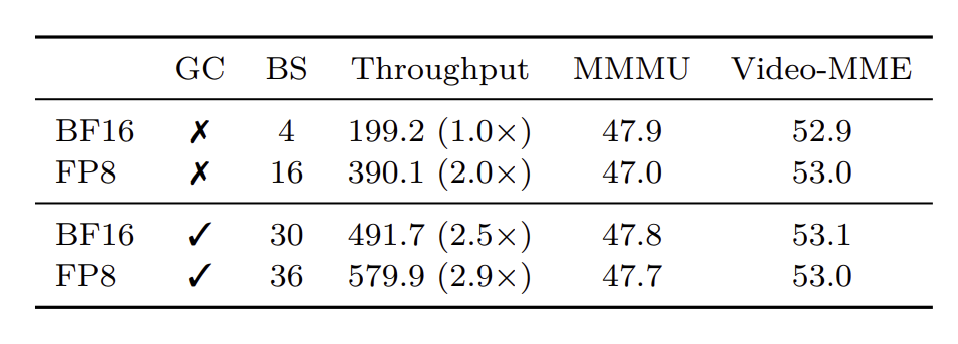
이미 많은 연구가 LLM에 FP8를 적용시켰고, 그에 따른 성능 향상을 확인했습니다. 본 연구에서도 선행 연구를 기반으로 FP8를 VLM에 적용시켜 보았습니다. LLM과 비교하여 VLM의 큰 차이점은 token의 길이입니다. 텍스트만 입력으로 받는 LLM과 달리, VLM은 그 입력값이 이미지가 될 수도, 영상이 될 수도 있어 token의 길이가 크게 차이날 수 있습니다. 때문에 token의 개수가 적을 수록 batch size을 늘려 얻을 수 있는 이득이 커집니다.
실험 결과 FP는 유의미한 성능 향상을 보여주었으며, 특히 Gradient Checkpointing을 사용하지 않는 경우 speedup이 2배 가량 차이나게 되었습니다(위 두 줄).
2.3. Efficient Fine-Tuning
본 연구는 VLM에서 finetuning을 수행하는 과정에서 아래 두 가지 사실을 알아냈습니다.
- Vision Encoder(VE)와 LLM은 learning rate를 서로 다르게 설정해야 한다.
- Fintuning 부분은 downstream task에 따라 의존적으로 선택되어야 한다.
일반적으로 PEFT기법을 이용해 VE와 LLM을 학습시킬 때는 VE가 LLM보다 5-50배 더 작은 값의 learning rate를 가져야 한다고 합니다. 또한 VE를 Layernorm을 이용해 finetuning할 때 LoRA와 비슷한 성능을 낼 수 있음을 확인했습니다.
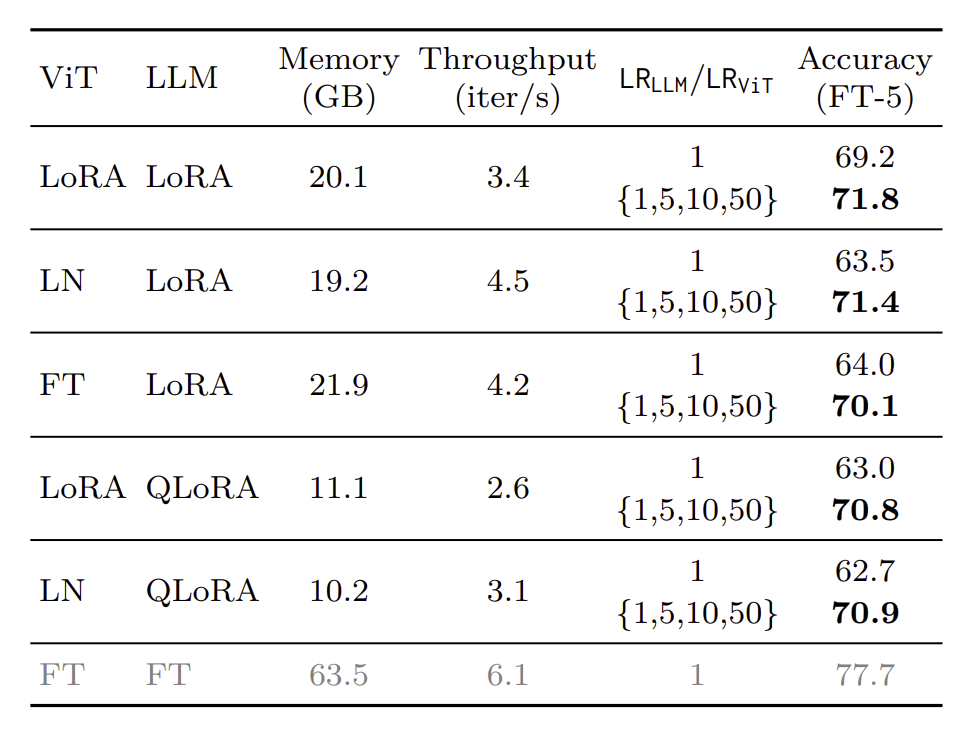
2.4. Efficient Deployment
본 연구는 quantization 기법을 이용하여 추론 엔진을 구현하였습니다. 추론은 크게 prefilling과 decoding 단계로 나뉩니다.
- Prefilling(compute-bounded) : 먼저 token compression으로 LLM의 연산량을 감소시킨 뒤, 병목이 된 vision tower를 해소하기 위해 W8A8 quantization을 적용합니다.
- Decoding(memory-bounded) : AWQ 방식을 기반으로 하여 LLM에 W4A16 quantization을 적용합니다.
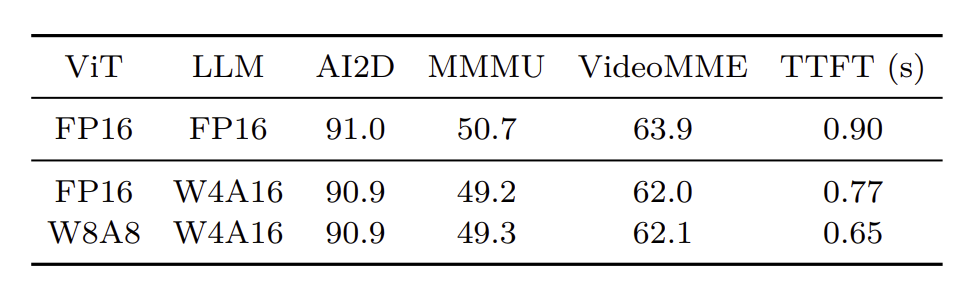
3. Experiments
3.1. Training Details
학습은 다음 다섯 단계를 거칩니다.
- Projector initialization
- Visual Encoder Pre-training (VEP)
- Token processor Pre-training
- Image instruction tuning
- Video instruction tuning
- 이 중 1, 3, 4 단계는 VILA 학습과정에 이미 포함되어 있습니다.
- 2단계는 token compression으로 인해 저하된 성능을 복구하기 위해 수행됩니다(2.1.1절).
- 5단계는 모델의 입력값을 영상으로 확장할 때 필요합니다.

3.2. Accuracy Results
3.2.1. Image Benchmarks

3.2.2. Video Benchmarks

3.3. Efficiency Results

4. More Capabilities
4.1. Temporal Localization
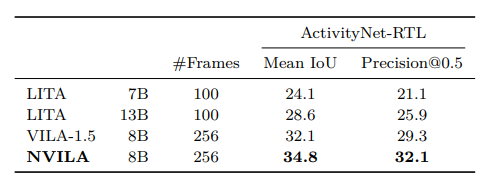
4.2. Robotic Navigation


4.3. Medical Application
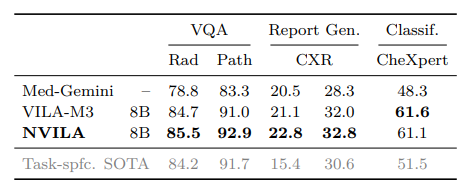
5. Related Work
- Visual Language Models(VLMs)
- Efficiency
6. Conclusion
본 연구는 효율성과 정확성을 향상시킨 VLM 모델 NVILA를 소개하였습니다. NVILA는 "scale-then-compress" 패러다임을 적용하여 고해상도의 이미지나 긴 재생 시간의 영상을 높은 정확도로 이해할 수 있게 되었습니다. 뿐만 아니라 temporal localization, robot navigation 등 다양한 분야에 응용될 수 있음을 보여 그 잠재성 또한 입증하였습니다.