영상 생성 분야에서 많이 쓰이기 시작한 모델인 FramePack에 대해 소개하는 논문입니다.
https://lllyasviel.github.io/frame_pack_gitpage/
FramePack
All results are computed by RTX 3060 6GB laptop with 13B HY variant. (Videos compressed by h264crf18 to fit in GitHub repos.)
lllyasviel.github.io
1. Introduction
Next-frame 혹은 Next-frame-section 예측 작업에 있어서 가장 중요한 두 가지 문제는 forgetting과 drifting입니다.
- Forgetting : 모델이 이전의 내용을 기억하거나 시간적 의존성을 유지하려 하면서 이전 내용을 잊어버리게 되는 현상
- Drifting : 시간이 지남에 따라 오류가 축적되면서 점차 결과값의 품질이 저하되는 현상
이 두 문제 사이에는 trade-off가 있습니다. Forgetting을 해결하기 위해 메모리를 증가하는 방법은 오류 축적을 더 빠르게 만들고, drifting을 해결하기 위해 오류 전파나 시간적 의존성을 완화하는 방법 또한 forgetting을 가속합니다.
Forgetting의 경우 단순히 인코딩하는 프레임의 수를 늘리는 방법이 있겠지만, transformer의 attention이 quadratic의 시간 복잡도를 가지므로 그 만큼 전체 계산량이 빠르게 늘어나게 됩니다. 또한 영상은 각 프레임마다 같은 visual feature들이 반복해서 나오는 경우가 많기 때문에, 단순히 프레임을 늘리면 불필요한 중복 정보들도 많아지게 됩니다.
Drifting은 상황이 조금 더 복잡합니다. Drifting은 일반적으로 하나의 프레임에서 발생한 오류가 이후 프레임들을 거치져 누적되고 전파되어 발생하는 현상입니다. 때문에 메모리 기억능력을 높이면 초기 오류가 발생할 가능성이 감소하면서도, 한 번 오류가 발생했을 때 그 오류를 기억하고 전파시킬 가능성 또한 증가하게 됩니다. 이 모순적인 상황 때문에 오류 수정 혹은 오류 전파 차단 기법을 설계하는데 주의가 필요합니다.
본 연구에서는 anti-forgetting 메모리 구조와 anti-drifting 샘플링 기법을 활용한 모델인 FramePack을 소개합니다. FramePack은 입력 프레임을 압축함으로 forgetting을 해결합니다. 이렇게 하면 프레임의 길이와 관계 없이 transformer가 계산할 context가 특정 상한 크기를 넘지 않도록 만듭니다. 또한 양방향 context 예측을 통해 drifting을 해결할 수 있습니다. 이는 프레임의 중간 부분을 생성하기 전 끝 부분을 먼저 구현하는 방법입니다. 여기에 더해 프레임을 역방향으로 생성하는 inverted temporal sampling도 사용합니다.
본 연구는 FramePack을 통해 HunyanVideo, Wan과 같은 기존의 영상 diffusion model들을 fintuning할 수 있음을 보여줍니다. 또한 FramePack이 수행하는 작업은 next-frame 예측이라 전체 영상 생성보다 생성하는 텐서의 양이 적고, 이 덕분에 timestep에 따라 생성되는 분포가 극단적으로 변하지 않는다는 특징이 있습니다(만약 전체 영상 생성이라면, noise의 분포가 초기 timestep에서는 대략적인 모양을 잡는 coarse 분포로 나타나고 timestep이 지날 수록 자세한 부분을 묘사하기 위해 fine 분포로 바뀌게 될 것입니다). 그 결과 덜 공격적인(less aggressive) diffusion scheduler가 만들어져 시각적인 품질이 향상되었습니다. 이는 forgetting과 drifting을 해결하는 중에 발견하게된 부가적인 성능입니다.
2. Related Work
2.1. Anti-forgetting and Anti-drifting
- Classifier-Free Guidance over history frames
- Anchor frames
- Compressing latent space
2.2. Long Video Generation
2.3. Efficient Architectures for Video Generation
3. Method
먼저 next-frame-section 예측을 수행할 때 Diffusion Transformers(DiTs) 모델을 사용한다고 가정합니다. 그리고 $T$개의 입력 프레임 $F \in \mathbb{R}^{T \times h \times w \times c}$이 주어졌을 때, $S$개의 프레임 $S \in \mathbb{R}^{S \times h \times w \times c}$을 새로 생성하는 상황을 고려합니다. 이 때 모든 계산은 latent space 안에서 수행됩니다.
보통 next-frame 예측에서는 $S = 1$(혹은 아주 작은 수)로 둡니다. 본 연구는 $T >> S$ 인 상황에 초점을 맞추었습니다. 프레임당 context length(프레임 당 토큰 길이)가 $L_f$(Hunyan/Wan/Flux 기준 480p에서 1560만큼의 길이를 가집니다)일 때, 기본 DiT는 전체 토큰 수 $L = L_f (T + S)$를 가집니다. 만약 $T$가 증가하면, 전체 context 계산량도 크게 증가할 것입니다.
3.1. FramePack
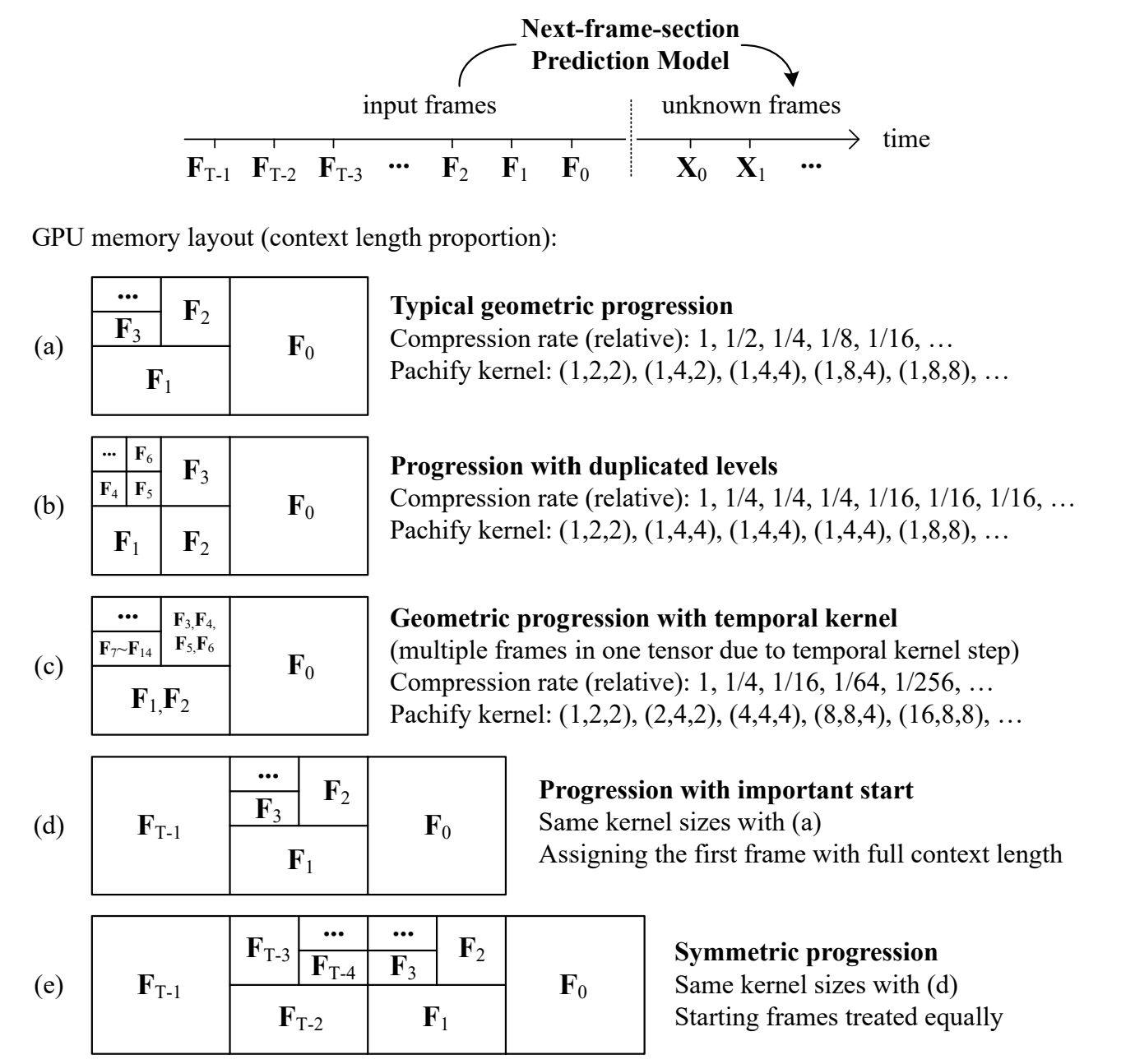
프레임을 생성하는데 있어서 입력 프레임들은 각각 그 중요도가 다르기에, 우리는 프레임 마다 우선순위를 부여할 수 있습니다. 일반성을 잃지 않고, 예측 프레임과 가까운 프레임일 수록 중요도가 높다고 가정합니다. 그렇다면 가장 중요한(=가장 가까운) 프레임 그룹을 $F_0$로 두고, 가장 덜 중요한(=가장 오래된) 프레임 그룹을 $F_{T-1}$로 둘 수 있습니다(따라서, $F_n$은 프레임 하나가 아니라, 프레임 다수 입니다).
각 프레임의 context 길이를 결정하는 length function $\phi(F_i)$를 다음과 같이 정의할 수 있습니다. $\lambda > 1$는 압축률이며, 덜 중요한 프레임일수록 압축률을 증가하여 context 길이를 더 짧게 만듭니다.
$ \phi(F_i) = \frac{L_f}{\lambda^i} \quad (1) $
프레임에 따른 압축은 transformer의 patchfiy* 방식으로 적용됩니다. 예를 들어 $\lambda = 2, i = 5$인 경우 patch 하나의 크기는 32픽셀이 됩니다. 따라서 총 context 길이는 다음을 따르게 됩니다.
* Patchfiy : 이미지를 transformer에 넣기 위해 작은 patch 단위로 쪼개어 각 patch를 토큰으로 변환하는 작업
$ L = S \cdot L_f + L_f \cdot \sum_{i=0}^{T-1} \frac{1}{\lambda^i} = S \cdot L_f + L_f \cdot \frac{1 - 1/\lambda^T}{1 - 1/\lambda} \quad (2) $
만약 $T \rightarrow \infty$인 경우, 아래처럼 수렴하게 됩니다.
$ \lim_{T \to \infty} L = S \cdot L_f + \frac{1}{1 - 1/\lambda} \cdot L_f = \left( S + \frac{\lambda}{\lambda - 1} \right) \cdot L_f \quad (3) $
따라서 FramePack의 context 길이는 입력 프레임의 길이와 관계 없이 상한선을 가지며, 이는 계산 시간을 일정한 불변량으로 만들 수 있습니다. 일반적으로 하드웨어는 2의 거듭제곱을 연산에 사용하므로 여기서도 $\lambda = 2$로 두었습니다. 이 경우 총 압축률은 $\frac{2}{2-1} = 2$이지만, 2 말고도 임의의 압축률도 항을 추가하여 표현할 수 있습니다(e.g. $ \frac{1}{2} + \frac{1}{8} + \sum_{i=0}^{\infty} \frac{1}{2^i}= 2.625$).
DiT에서의 patchifying 연산은 3차원으로 이루어지기 때문에 context 길이 만큼의 크기를 가지는 3D 커널을 $(p_f, p_h, _pw)$의triplet으로 나타낼 수 있습니다(f: 프레임 번호, h: 높이, w: 너비). 이 조합은 같은 압축률에 대해서도 여러가지가 있기 때문에, 설계 단계에서 다양한 값으로 바꿔가며 생성이 가능합니다.
3.1.1. Independent patchifying parameters
신경망에서 매개변수가 압축률에 관계 없이 일정하다면 안정적인 학습을 진행할 수 있습니다. 따라서 본 연구는 입력값으로 가장 많이 쓰인 kernels들인 (2, 4, 4), (4, 8, 8), 그리고 (8, 16, 16)을 독립적인 매개변수 크기로 두었습니다. 이 보다 큰 압축률을 가지면, downsampling을 거쳐 이 세 가지중 가까운 값으로 바꾸어 계산합니다.
3.1.2. Tail options
이론적으로 FramePack은 임의 길이의 영상에 대해서 고정된 context 길이의 토큰을 만들어내지만, 만약 입력 영상의 프레임이 굉장히 길다면, $F_{T-1}$에 속한 tail area는 굉장히 작은 크기의 token을 반환하게 됩니다(e.g. 1픽셀). 본 연구는 이런 꼬리 경우를 세 가지 방식으로 처리해 보았습니다.
- 그냥 없애기
- 일정 시점 이후로는 $F_n$ 마다 전부 1픽셀로 고정
- 전체 $F_n$을 average poolng 처리
실험 결과 세 가지 방식 모두 무의미한 차이를 보였다고 합니다. 애초에 꼬리 경우는 그만큼 next-frame 예측에 가장 중요하지 않은 부분인 만큼, 무시해도 좋은 차이일 것입니다.
3.1.3. RoPE alignment
입력 프레임들을 서로 다른 압축률에 따른 kernel들로 처리하면, 각 프레임 그룹마다 토큰 개수가 달라지게 됩니다. 때문에 RoPE* 정렬을 할 때, 위치 뿐만 아니라 그 크기도 정렬할 필요가 있습니다. 따라서 RoPE의 위상들을 downsampling(average pooling을 사용한다고 합니다)하여 크기를 맞추게 됩니다.
* RoPE(Rotary Position Embedding) : 각 토큰 위치마다 위치 정보를 복소수의 sinusoidal 방식으로 부호화(=위상, phase)하는 방식
3.2. FramePack Variants
실용성과 최적화를 위해 여러가지 변형들을 고안해 보았습니다.
3.3. Anti-drifting Sampling
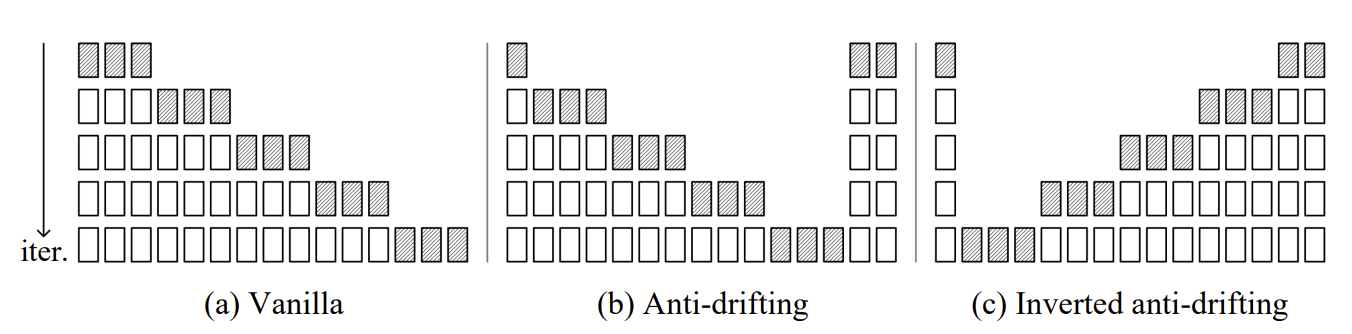
Drifting은 일반적으로 기본적인 sampling(과거 프레임들을 기반으로 생성하는 경우)에서만 일어나고, 미래의 프레임을 함께 보여주면 현상이 일어나지 않음을 관찰했습니다. 이를 기반으로 본 연구는 bi-directional context 기법을 적용하였습니다.
(c)는 Anti-drifting을 뒤집은 경우인데, 사용자가 이미지를 입력값으로 넣었을 때 첫 번째 프레임으로 바로 사용할 수 있기 때문에 image-to-video 작업에 효과적인 접근법입니다((b)는 첫 번째 프레임으로 사용하지 않고 새로 생성합니다).
세 가지 접근법 모두 임의 길이의 영상 생성 작업이 가능합니다.
4. Experiments
4.1. Ablative Naming
실험의 편의성을 위해 다음과 같이 각 모델의 변형에 대한 명명법을 정의했습니다.

이에 따르면, 위에서 언급했던 vanilla 모델, anti-drifting 그리고 inverted anti-drifting은 다음과 같이 표기하게 됩니다.
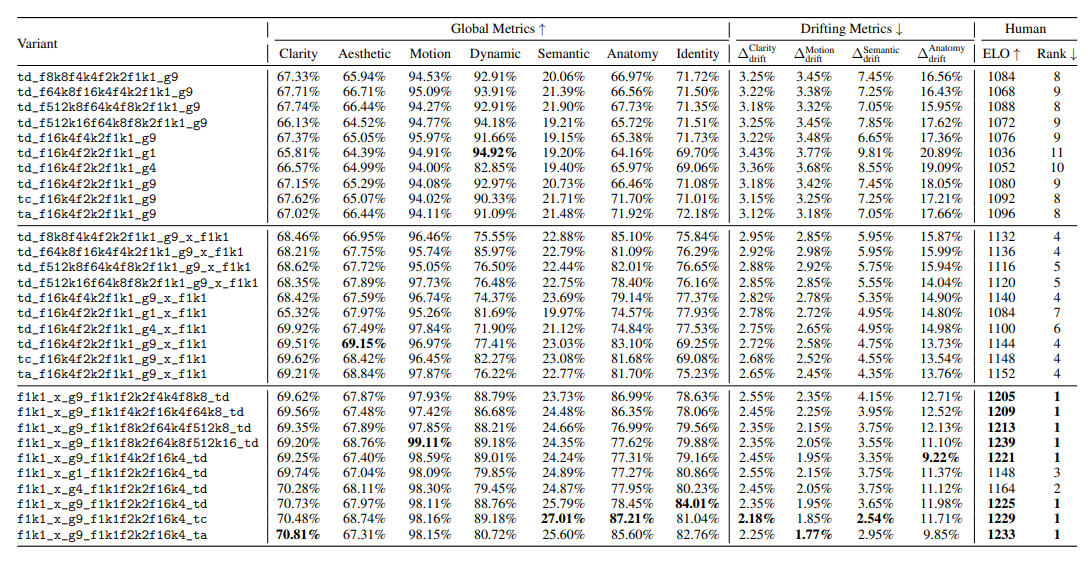
| Vanilla | td_f16k4f4k2f1k1_g9 |
| Anti-drifting | td_f16k4f4k2f1k1_g9_x_f1k1 |
| Inverted anti-drifting | f1_k1_x_g9_f1k1f4k2f16k4_td |
4.2. Base Model and Implementation Details
본 연구에서는 Wan과 HunyuanVideo 모델에 FramePack을 적용하였습니다. Wan의 경우 2.1. 버전 모델을 사용하였지만, HunyuanVideo는 Wan과 성능을 비슷하게 맞추기 위해 아래 몇 가지 수정사항을 거쳤습니다.
- Vision encoder에 SigLip-Vision 사용
- Tencent의 내부 MLLM 의존성 제거
- LLama3.1.의 텍스트 부분만 남겨 multi-modal 기능 제거
- 추가 학습
- Dataset : LTXVideo's dataset
- GPU : H100 clusters
- Time : 48h
- Batch size : 64, 480p resolution
- Optimizer : Adafactor
- Learning rate : 1e-5
- Gradient norm clip : 0.5
4.3. Evaluation Metrics
각각 text-to-video와 image-to-video에 대해 512개의 프롬프트를 실행시켜 평가를 진행했습니다. 긴 영상은 30초, 짧은 영상은 5초의 길이를 가집니다.
4.3.1. Multi-dimension Metrics
Benchmarks : VBench, VBench2, etc.
| 평가항목 | 내용 | 모델 | 비고 |
| Clarity | 명확성 | MUSIQ image quality predictor | |
| Aesthetic | 심미성 | LAION aesthetic predictor | |
| Motion | 움직임의 자연스러움 | VBench frame interpolation model | Dynamic과 trade off |
| Dynamic | 동적 정도 | RAFT | Motion과 trade off |
| Semantic | 텍스트 프롬프트 맥락 | ViCLIP | |
| Anatomy | 손, 머리 등인체 요소 | ViT | |
| Identity | 얼굴 | ArcFace, RetinaFace |
4.3.2. Drifting Measurements
Drifting을 정량평가하기 위해 start-end contrast 지표를 고안해냈습니다. start-end contrast는 영상의 처음과 끝 사이의 차이를 비교한 것으로, 임의의 벤치마크 $M$과 평가하고자 하는 영상 $V$에 대해 다음과 같이 정의됩니다. 각 $V_{start}$와 $V_{end}$는 처음과 끝 15% 분량의 프레임들에 해당됩니다.
$\Delta^M_{drift}(V) = |M(V_{start}) = M(V_{end})| \quad (4)$
4.3.3. Human Assessments
추가로 각 ablative 모델에 대해 100개의 영상을 생성하여 사람들을 대상으로 A/B 테스트를 시행했습니다.
4.4. Ablative Results
4.5. Comparison to Alternative Architectures
