CVPR 2025에서 포스터 세션으로 발표된 논문입니다. 2D 기반 VLM 모델을 3D 동작 추론에 사용한 InteractVLM에 대해 소개합니다.
https://interactvlm.is.tue.mpg.de/
InteractVLM: 3D Interaction Reasoning from 2D Foundational Models
We introduce InteractVLM, a novel method to estimate 3D contact points on human bodies and objects from single in-the-wild images, enabling accurate human-object joint reconstruction in 3D. This is challenging due to occlusions, depth ambiguities, and wide
interactvlm.is.tue.mpg.de
1. Introduction

인간-물체 상호작용(Human-Object Interaction, HOI)는 활발히 연구되고 있는 주제입니다. 하지만 이를 한 장의 이미지로만 추론하는 것은 깊이, 투명도 등 여러가지 요인으로 인해 상당히 어렵습니다.
비록 3차원 상에서 인간 동작 또는 물체를 추론하는 모델은 여러가지가 있지만, 이 둘을 모두 포함하는 모델은 찾기가 힘듭니다. 본 연구의 목적은 하나의 이미지를 받았을 때 인간과 물체의 상호작용으로 재구성하는 모델을 학습시키는 것입니다. 하지만, 이를 위해 필요한 인간 - 물체 상호작용과 이미지가 서로 짝지어져 있는 데이터셋이 많지 않아 수집하기 어렵다는 문제가 있습니다.
또한 인간 - 물체 상호작용은 한 번에 여러개의 물체와 이루어지는 경우도 많기에, 기존의 간단한 binary classification으로는 반영하기 어렵니다. 따라서, 본 연구에서는 새로운 "Semantic Human Contact"을 예측하는 작업을 만들어 냈습니다. 이는 입력 이미지르 바탕으로 사람의 신체와 물체가 상호작용하는 지점을 예측할 수 있습니다.
그리고 본 연구는 Vision-Language Models(VLMs)이 기본적으로 시각적인 정보를 풍부하게 가지고 있으므로, 해당작업의 추론과정에 도움을 줄 수 있다고 주장합니다. 그리하여, 기존의 VLMs을 사용하여 새로운 프레임워크인 InteractVLM을 선보이게 되었습니다.
InteractVLM의 골자는 VLM를 기반으로 하여 추론 모델을 학습시켰다는 것입니다. 이 VLM에 LoRA를 추가하면 3D 인간-물체 상호작용에 대한 이해도를 높일 수 있습니다. 그렇게 하면, RGB 이미지 하나만 주어져도 모델은 질문을 통해 인간과 물체의 접촉 위치를 추론하는데 필요한 reasoning token을 만들어낼 수 있습니다.
하지만 그 과정은 생각보다 간단하지 않습니다. 일단 이 reasoning token을 기존에 존재하는 localization 모델이 참조하게 해서 3D 접촉지점을 표시하는 방법이 있겠으나, 이 localization 모델들은 2D 공간을 대상으로만 동작한다는 문제가 있습니다. 우리가 필요한 것은 3D 공간 상에서의 접촉지점이므로, 이 문제를 2D 공간에서 동작 가능하도록 재구성할 필요가 있습니다.
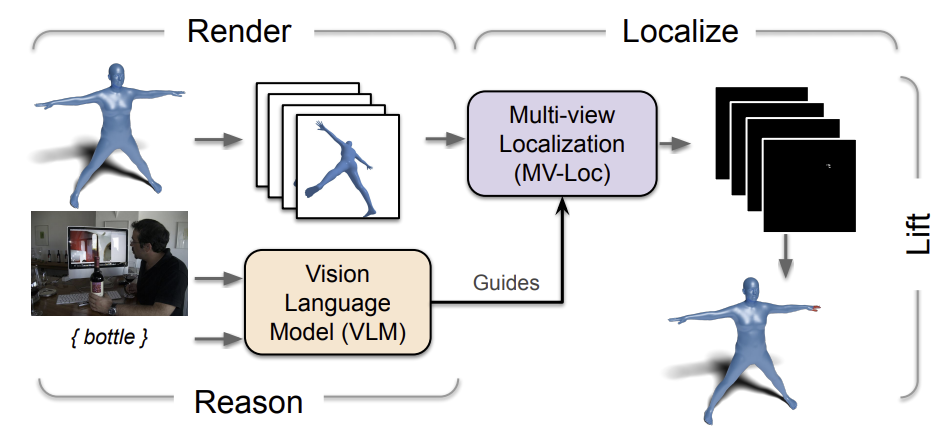
그리하여, 본 연구에서는 새로운 Render-Localize-Lift(RLL) 프레임워크를 만들었습니다. RLL은 세 단계로 이루어져 있습니다([그림 2] 참고).
- 사람의 3D 모델 SMPL+H와 물체의 3D 모델을 multi-viewpoint 2D 이미지로 렌더링
- 이 이미지를 localization 모델에 넣어 인간과 물체의 접촉 위치를 2D 값으로 추론
- 추론한 2D 접촉 위치를 3D 공간으로 변환(back-projection 사용)
하지만 이렇게 3D 공간을 multi-view의 여러 2D 이미지로 바꾸어도, localization 모델은 이것들이 multi-view라는 사실을 모르므로(2D 기반 모델이기 때문에) multi-view consistency와 관계 없이 지점을 추론하기 쉽습니다. 이 문제는 단순히 카메라 매개변수를 함께 추가하는 것 만으로 해결할 수 없어서, 새로운 Multi-view Localization 모델인 MV-Loc을 만들게 되었습니다. MV-Loc는 두 단계의 작업을 수행합니다.
- Multi-view 이미지들을 만드는데 사용한 카메라 매개변수를 통해 reasoning token을 변환
- 생성한 접촉지점들이 3D 공간 상에서 일관성을 가지도록 강제
InteractVLM은 VLM과 MV-Loc을 사용하여 인간과 물체 사이의 3D 접촉지점을 예측할 수 있습니다. 본 연구는 DAMON과 PIAD 데이터셋을 통해 기존의 binary contact 작업과 여기서 새로 제시한 semantic contact 작업을 수행하여 InteractVLM의 성능을 정량적으로 평가하였고, 이전 모델들 보다 뛰어난 성능을 보였다고 합니다.
마지막으로, InteractVLM의 결과값을 이용하여 3D HOI 재구성 작업도 수행했다고 합니다. 이는 보통 이미지의 모호한 표현으로 인해 정확히 구현하기 어려운 작업인데, 본 연구에서는 InteractVLM이 추론한 접촉지점을 제약조건으로 두어 인간과 물체 모두 해당 지점에 고정되도록 만들었다고 합니다. 이는 최초로 '추론한 지점을 이용해 임의의 이미지에 대한 3D HOI를 예측한 기법'이라고 말합니다.
2. Related Work
- Large Vision-Language Models
- 3D Human and Object from Single Images
- 3D Human-Object Interaction
- Joint 3D Human-Object Reconstruction
3. Method
3.1. Input Representation
| 형식 | 크기 | |
| 이미지 ($I$) | 벡터 | $I \in \mathbb{R}^{H \times W \times 3}$ |
| 인간 ($H$) | vertex $V$개의 SMPL+H* 3D body mesh | $V^H \in \mathbb{R}^{10475 \times 3}$ |
| 인간 접촉지점 ($C^H$) | 각 vertex 마다의 이진 라벨 | $C^H \in {0, 1}$ |
| 물체 ($O$) | 3D point cloud | $O \in \mathbb{R}^{N \times 3}$ |
| 물체 접촉지점 ($C^O$) | 각 point 마다의 연속적인 값 | $C^O \in [0, 1]$ |
이미지 - HOI 쌍의 데이터셋이 없어서, 대신 대규모 3D affordance(contact와 유사하기 때문에) 데이터셋을 사용하였습니다. Affordance는 물체가 사용자와 상호작용할 수 있게 할 만한 특성이므로, 물체 표면에서 다양한 목적에 따라 접촉이 일어날 가능성을 나타내기도 합니다.
* SMPL+H : 인간 메쉬 모델중 하나
3.2. Overview of InteractVLM
InteractVLM은 인간-물체 상호작용 데이터셋이 부족하다는 단점을 VLM을 활용함으로서 해결했습니다. [그림 3]을 보면 InteractVLM은 VLM(주황색)과 MV-Loc(보라색) 두 부분으로 이루어져 있는데, MV-Loc는 VLM의 guidance를 기반으로 인간과 물체 양쪽 모두에 접촉지점을 표시하는 역할을 합니다. VLM의 , MV-Loc의 입력값은 인간과 물체의 3D 구조 $H$와 $O$입니다.
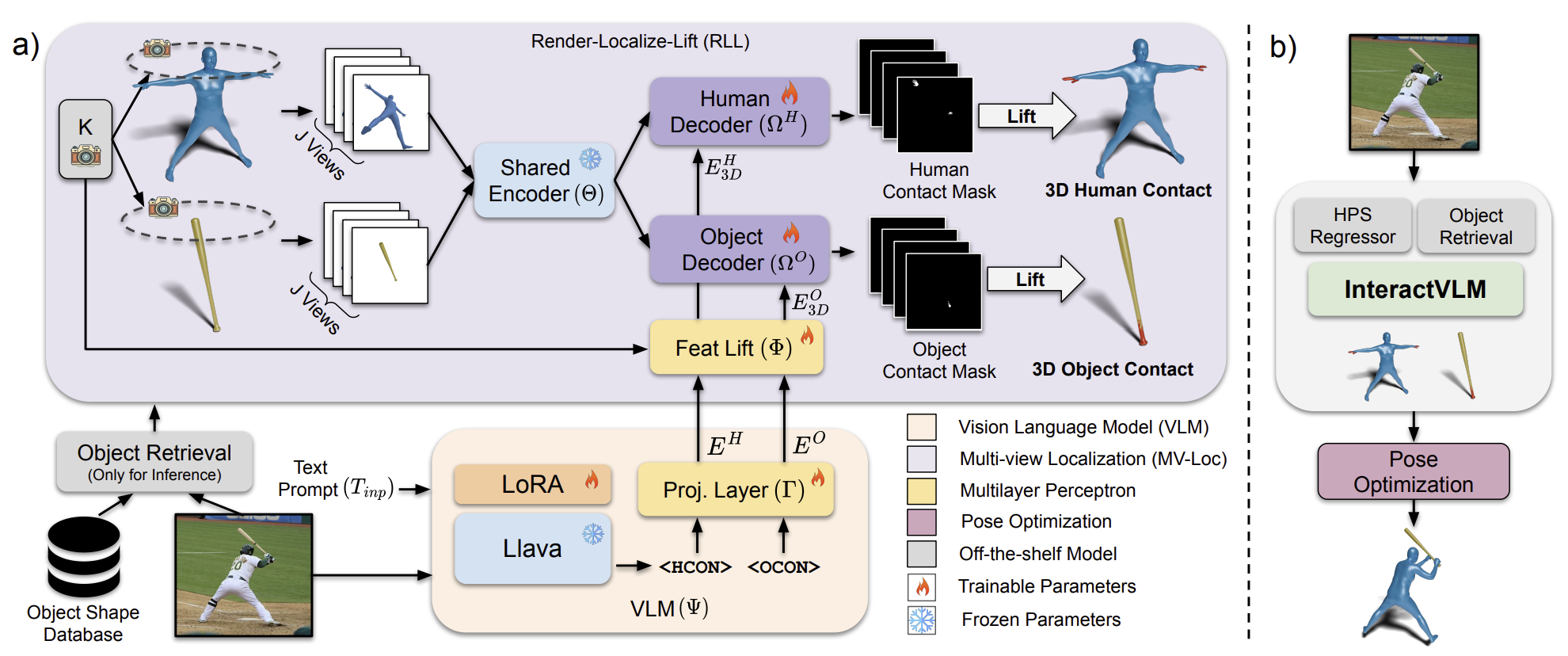
3.3. Interaction Reasoning through VLM
VLM $\Psi$는 핵심적인 추론 작업을 수행합니다. 입력값으로 이미지 $I$와 텍스트 프롬프트 $T_{inp}$를 받아 출력값으로 텍스트 프롬프트 $T_{out} = \Psi(I, T_{inp})$을 생성합니다. $T_{out}$은 접촉정보를 나타내는 토큰인 <HCON>(Human CONtact)과 <OCON>(Object CONtact)을 가집니다.
MV-Loc로 보내기 전에, VLM의 마지막 계층에서 <HCON>과 <OCON>에 해당하는 embedding을 사영 계층 $\Gamma$로 보내 feature embedding $E^H$와 $E^O$를 계산합니다.
$E^H = \Gamma(H_{HCON})$
$E^O = \Gamma(H_{OCON})$
VLM의 토큰 예측에 대한 손실함수는 cross-entropy 형태로 정의합니다.
$\mathcal{L}_{\text{token}} = - \sum_{i=1}^{N} \left( \mathbf{T}_{\text{gt}}^{(i)} \cdot \log\left(\mathbf{T}_{\text{pred}}^{(i)}\right) \right) \quad (1)$
$\mathbf{T}_{\text{gt}}$는 ground-truth 텍스트, $\mathbf{T}_{\text{pred}}$는 예측한 텍스트($T_{out}$)입니다.
3.4. Interaction Localization through MV-Loc
MV-Loc은 인간과 물체가 공유하는 encoder $\Theta$와 별개로 가지는 decoder $\Omega^H$, $\Omega^O$를 가지고 있습니다. 그리고 RLL 프레임워크를 사용하여 아래 세 단계의 과정을 수행합니다.
3.4.1. Render 3D → 2D
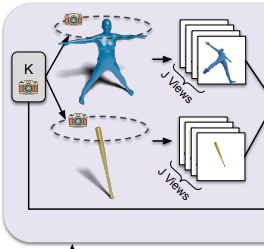
입력값은 인간과 물체의 입체구조인 $H$, %O%입니다. 인간 물체는 SMPL+H 형식으로, 모호함을 최대한 배제하기 위해 별 모양 자세(大)로 들어갑니다. 물체는 point cloud 형식으로 들어갑니다. 각 입체구조는 $J$개의 고정된 시점(카메라 매개변수 $K$ 포함)에 대한 multi-view rendering으로 변환됩니다.
$R^{H, O} = \{R_j\}^J_{j=1}$
이 입체구조들을 따로 색상이나 텍스쳐가 없기 때문에, normal값과 NOCS map을 이용한 point cloud로 색상을 입혔습니다.
3.4.2. Localize in 2D
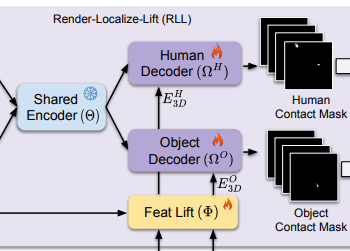
입력값은 랜더링된 이미지 $R^H, R^O$이며, 접촉지점을 가리키는 masking $M^H, M^O$를 출력값으로 내놓습니다. 여기에 공간적/맥락적 단서를 위해 VLM(3.3절)에서 계산한 feature embedding $E^H, E^O$도 사용합니다.
하지만이 feature embedding을 순전히 2D 이미지만을 위한 것이어서, 3D의 multi-view consistency가 반영되지 않습니다. 때문에 lifting network $\Phi$를 따로 만들어 카메라 매개변수 $K$와 feature embedding $E^H, E^O$를 받아 multi-view consistency가 반영된 $E^{H, O}_3D$를 계산합니다.
$E^{H, O}_3D=\Phi(E^{H,O}, K)$
$E^{H, O}_3D$ 값과 encdoer의 출력값을 decoder에 넣으면 인간과 물체 각각의 masking을 계산할 수 있습니다.
$M^{H, O} = \Omega^{H, O}(R^{H, O}, E^{H, O}_3D) \quad (2)$
손실함수는 입체구조의 윤곽선 안쪽 영역, 즉 예측이 의미 있는 부분에 대해서만 계산합니다. 예측한 masking $M$과 ground-truth masking $\hat{M}$ 두 개가 잘 겹치게 하기 위해, focal-weighted Binary Cross Entropy(BCE) loss와 Dice loss를 사용하였습니다.
$\mathcal{L}_{\text{BCE}} = -\alpha (1 - p_M)^{\gamma} \log(p_M) - (1 - \alpha) p_M^{\gamma} \log(1 - p_M) \quad (3)$
$\mathcal{L}_{\text{Dice}} = 1 - \frac{2 \sum M \cdot \hat{M} + \epsilon} {\sum M + \sum \hat{M} + \epsilon} \ quad (4)$
- $p_M$ : 예측한 mask 확률
- $\alpha$ : class 불균형 조절 계수
- $\gamma$ : focal loss 조절 계수
- $\epsilon$ : 0으로 나뉘는 것을 방지하는 용도
3.4.3. Lift 2D → 3D
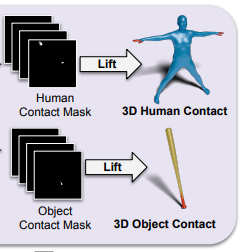
추론한 2D masking $M^H, M^O$들은 3.4.1절의 단계를 반대로 수행하여 3D 입체구조 $C^H, C^O$로 다시 변환됩니다.
인간 접촉지점에 대한 손실함수는 focal loss와 sparsity regularization을 사용합니다. 이는 적절한 부분에서 양성 예측(true-positive)을 하도록 하면서 동시에 적절하지 않은 부분에서 음성 예측(false-positive)을 하지 않도록 유도합니다.
$\mathcal{L}_C^H = \alpha (1 - p_{hC})^\gamma \log(p_{hC}) + \lambda \| C^H \|_1 \quad (5)$
- $p_{hC}$ : 접촉 확률
- $\lambda, \alpha, \gamma$ : 조절 계수
물체 접촉지점에 대한 손실함두는 Dice와 MSE loss를 사용합니다.
$\mathcal{L}_C^O = \mathcal{L}_{\text{Dice}}(C^O, \hat{C}^O) + \beta \| C^O - \hat{C}^O \|_2^2 \quad (6)$
$\beta$ : 가중치 계수
$\hat{C^O}$ : ground-truth 접촉지점
3.5. Implementation Details
3.5.1. Architecture
- VLM : LLaVA
- MV-Loc : SAM
- Feature-lifting network($\Phi$) : (spatial-understanding) - (view-specific) - (sigmoid)
- Spatial-understanding network : (128-FC) * 2 - (ReLU)
3.5.2. Training
Rank-8 LoRA와 DeepSpeed를 사용하여 학습하였습니다(Decoder는 LoRA 없이 학습되었습니다).
- batch size : 8
- GPU : A100 × 4
- epoch : 30
3.5.3. Datasets
- human contact : DAMON
- 3D object affordance : PIAD
- human-object reconstruction : DAMON, PIAD, 3DIR
3.5.4. Evaluation metrics
- human contact : F1, 정확도, 재현율 (threshold = 0.5), geodesic 거리 측정
- object contact : SIM, MAE, Area Under ROC Curve(AUC), IoU
4. Experiments
4.1. "Binary Human Contact" Estimation
물체 수와 관계 없이 인간 신체의 각 vertex마다 접촉지점이 존재하는지를 예측합니다.
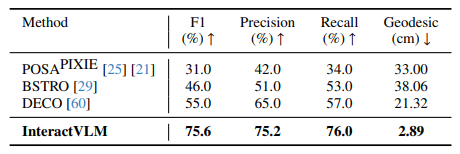
4.2. "Semantic Human Contact" Estimation
여러 개의 물체와 상호작용하는 상황을 위해 어떤 물체가 어디에 접촉하는지를 판단합니다. Baseline은 DECO 모델을 multi-class prediction으로 바꾸어 만들었습니다.


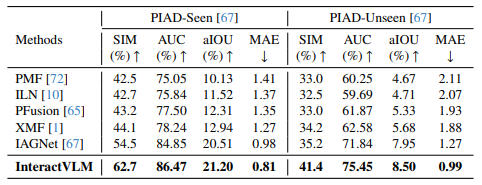
4.3. Object Affordance Prediction
물체가 주어졌을 때 상호작용 가능할 만한 지점을 예측합니다. 데이터셋으로 PIAD가 주어졌을 때와 주어지지 않았을 때 모두 비교합니다.
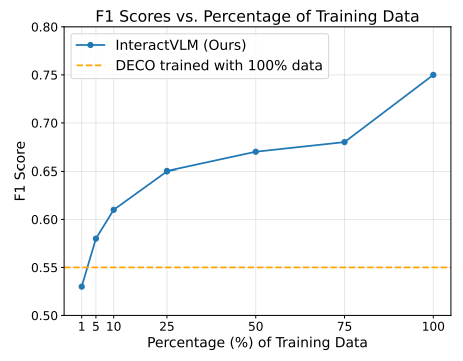
4.4. Reliance on 3D Annotations
3D 학습에 따른 InteractVLM의 성능을 확인하기 위해 DAMON 데이터셋의 비율을 다르게 하여 F1 점수를 측정하였습니다.
5. Joint Human-Object Reconstruction

5.1. Initializing 3D body pose & shape, object shape
인간 mesh $H$는 OSX를 이용해 3D SMPL-X의 형태로 예측합니다. 물체 mesh $O$는 OpenShape 데이터베이스를 이용합니다.
5.2. Initializing 3D object pose
InteractVLM을 이미지 $I$에 적용시켜 접촉지점 $C^{H, O}$를 생성합니다. 그 후, ICP 알고리즘을 사용하여 $C^O$에 있는 지점들을 $C^H$로 이동시킵니다. 여기서 잘못되는 것을 방지하기 위해 각 지점의 normal 값이 일치하도록 만듭니다(각도는 같되 바라보는 방향은 반대가 되도록). 이 과정에서 물체의 회전행렬($R^O$)과 이동 벡터($t^O$)를 구합니다.
5.3. Optimizing 3D object pose
$R^O, t^O, s^O $(scale)에 대한 최적화를 수행합니다(얼마나 변형해야 $C^H$에 잘 맞게 되는지). 최적화는 아래 세 개의 식 값을 최소화 하는 방향을 진행됩니다.
$E = E_M + \lambda_C E_C \quad (7)$
$E_M = IoU(\hat{M}, M) + \left\| \widehat{M}^c - M^c \right\|_2 \quad (8)$
$E_C = \frac{1}{|C^H||C^O|} \sum_{i \in |H|} \sum_{j \in |O|} C^H_i C^O_j \left\| V^H_i - V^O_j \right\|_2 \quad (9)$
- $E_M$ : mask loss
- $E_C$ : contact loss
- $IoU$ : IoU 함수(Intersection over Union)
- $\hat{M}, M$ : 예측 mask, ground-truth mask
- $\hat{M^c}, M^c$ : 마스크 중심(mean pixel)
- |C^{H, O}| : 접촉지점 개수
- |H|, |O| : vertex 개수
- $V^H_i, V^O_j$ : i 번째 인간 mesh vertex, j 번째 물체 mesh vertex
- $C^H_i, C^O_j$ : i 번째 인간 mesh vertex의 접촉 여부, j 번째 물체 mesh vertex 의 접촉 여부
$E_M$은 3D 구조가 이미지와 잘 정렬되도록 만들고, $E_C$는 3D 구조의 접촉지점이 인간 신체에 잘 반영되도록 합니다.
5.4. Qualitative Results
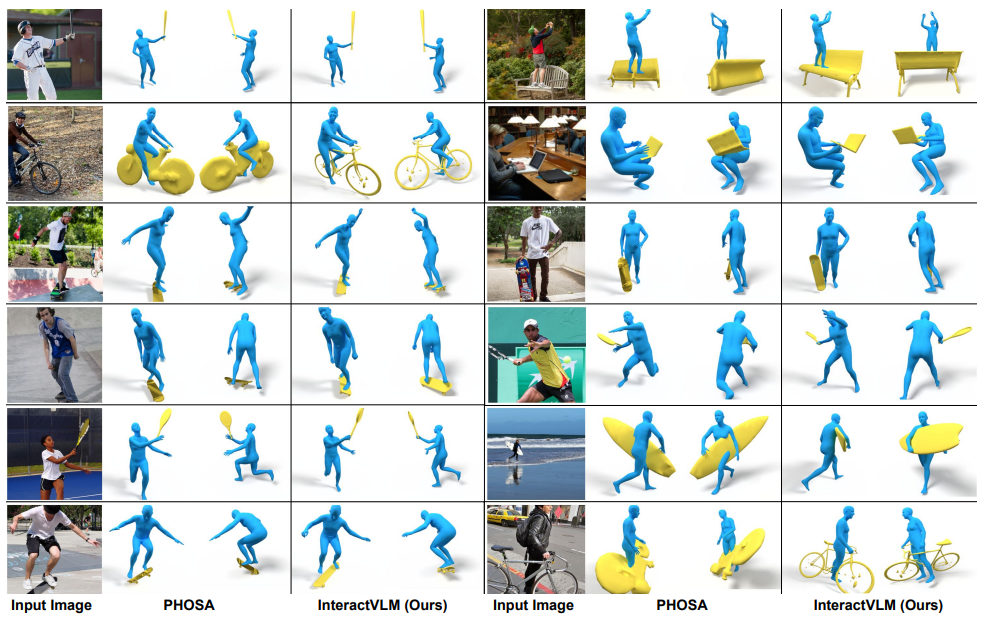
5.5. Perceptual Study
PHOSA모델과 비교하여 InteractVLM은 62%의 선호도를 얻었습니다.
6. Conclusion
본 연구는 하나의 이미지로부터 사람과 물체 모두를 추론할 수 있는 새로운 모델인 InteractVLM을 소개하였습니다. InteractVLM은 VLM을 활용하기 때문에 학습에 필요한 3D 주석들로부터 비교적 자유롭습니다. 실제로 이 모델은 여러 개의 물체들과 동시에 상호작용하는 상황에 대한 "Semantic Human Contact"에서 뛰어난 성능을 보였습니다. 마지막은로, 모델을 통해 추론된 접촉지점들을 기반으로 인간-물체의 3D 재구성 작업 또한 수행할 수 있었습니다.
'Reveiw > Paper' 카테고리의 다른 글
| [review] NVILA: Efficient Frontier Visual Language Models (0) | 2025.07.07 |
|---|---|
| [review] Yo'Chameleon:Personalized Vision and Language Generation (3) | 2025.07.04 |
| [review] Adding Conditional Control to Text-to-Image Diffusion Models (0) | 2025.07.01 |
| [review] Attention Is All You Need (0) | 2025.06.29 |
| [review] Visual Instruction Tuning (0) | 2025.06.26 |