CVPR 2025에서 포스터 세션으로 발표된 논문입니다. 개인화된 VLM인 Yo's Chameleon을 소개합니다.
https://thaoshibe.github.io/YoChameleon/
🦎 Yo'Chameleon: Personalized Vision and Language Generation
Yo'Chameleon: Personalized Vision and Language Generation!
thaoshibe.github.io
1. Introduction

오늘날 Large Multimodal Models(LMM)은 여러 분야로 연구되어 다양한 애플리케이션에 적용되었습니다. 특히 시각적 정보와 텍스트 정보를 동시에 처리하는 기능은 GPT-4o 등을 통해 많이 선보여졌으며, 사용자 상호작용에 많은 영향을 끼쳤습니다.
하지만 LMM은 여전히 개인화된 명령은 잘 수행하지 못하는 한계점이 있습니다. 예를 들어 키우는 개의 이름을 <bo>라고 했을 때, <bo>에 대한 정보가 사전에 없는 한 "<bo>가 책을 읽는 사진을 만들어줘" 같은 query를 처리하지 못하는 것입니다. 실제로 우리는 모두 각자만의 소유물 혹은 관계를 가지로 살아간다는 점에서 이런 문제는 상당히 치명적인 단점이 될 수 있습니다. 좀 더 실용적이고 의미 있는 AI가 되기 위해서는 보편적인 지식 말고도 이렇게 고도로 개인화된 정보를 이해하고 생성하는 것도 중요합니다.
이 때까지 LLMs이나 이미지 생성 모델에서 이러한 개인화 기술이 많이 연구되었습니다. LLaVA와 같은 VLM의 경우도 개인화를 처리한 부분이 있지만 이 경우 출력값으로 텍스트만을 내놓는다는 한계점이 있었습니다. 본 연구는 여기서 더 나아가 개인화 기술을 multimodal로 확장하고자 합니다.
본 연구는 두 가지 문제에 집중합니다. 첫 번째는 '치명적 망각(catastropic forgetting)'입니다. 일련의 연구를 통해 LMM이 finetuning을 통해 이미지 생성을 학습하면, 그 만큼 단어에 대한 지식을 잊어버린다는 것을 알아냈습니다. Soft prompt learning*이 이미지 이해 작업에 있어서 개인화를 잘 수행하긴 하지만, 3 - 5개의 이미지 만으로는 고품질의 이미지를 만들어내지 못한다는 한계점이 있습니다.
* Soft prompt learning : 모델 매개변수는 그대로 둔 채 입력값 앞에 학습 가능한 토큰을 넣어 새로운 개념을 학습시키는 방법
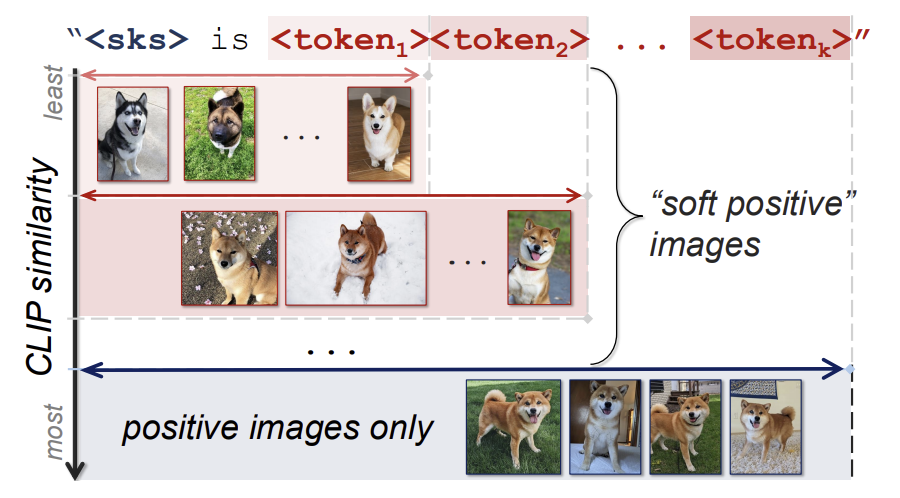
이는 학습 이미지의 개수가 부족하기에 생기는 문제이므로, 300개 정도의 이미지를 통해 soft prompt learning을 수행하면 LLM이 이전 지식을 보존하면서 finetuning을 해낼 수 있습니다. 하지만 그렇다고 사용자가 개인화 학습을 위해 300장에 이르는 이미지를 넣는 것은 그닥 실용적이지 않습니다. 때문에 본 연구는 개인화 학습에 사용할 이미지(positive image)와 비슷한 시각적 특성을 지니는 soft-positive image를 사용하여 데이터셋을 보충하였습니다. 또 이를 효과적으로 사용하기 위해, positive image과 soft-positive image의 차이에 따라 프롬프트의 길이가 달라지는 adaptive prompt length 전략을 사용하였습니다. 예를 들어, 사용자의 시바견에 대해 학습시킬 때 실제 그 시바견의 이미지(=positive image)에 더해 그 시바견과 비슷한 시바견의 이미지(=soft-positive image)를 함께 데이터셋에 넣게 되고, 그 이미지가 실제 시바견과 비슷할 수록 이미지를 묘사하는 프롬프트는 길어지게 됩니다.
두 번째 문제는 LMM에서 이미지 생성과 이미지 이해 능력의 호환성에 대한 것입니다. 본 연구는 실험을 통해 한 가지 작업을 위해 학습된 soft prompt가 다른 작업에도 적용되면 작업이 잘 수행되지 않음을 확인했습니다. 예를 들어 이미지 이해를 위해 학습시킨 soft prompt가 이미지 생성 작업에서는 잘 먹히지 않는 식입니다. 그냥 여러 종류의 작업에 대해 동시에 학습시키면 될 것 같지만, 이 또한 실험한 결과 각 작업에서 최적의 성능을 보이지 않는 애매한 결과가 나왔다고 합니다.

본 연구는 이를 해결하기 위해 dual soft prompt를 소개합니다. 이는 텍스트 생성과 이미지 생성을 위한 프롬프트를 각각 가지고 있으며, self-prompting을 통해 query를 만들기 전에 모델이 작업 종류를 정하여(e.g. 이해 or 생성) 그에 맞는 프롬프트를 사용하게 됩니다.
2. Related Work
- Personalization for Large Mulimodal Models
- Parameter-Efficient Fine-Tuning (PEFT)
- Hard negative image mining
3. Yo'Chameleon
우리가 개인적으로 학습시키고 싶은 개념에 대한 이미지들을 $I^1, I^2, ... , I^n$이라고 합시다. 우리의 목표는 이것들을 특별한 토큰 <sks>으로 바꾸어 LMM을 이용해 아래 두 목표를 수행하는 것입니다.
- 개인화된 언어 생성(e.g. "<sks>에 대해 묘사해줘", "<sks>은 그림에서 어디에 있지?")
- 개인화된 이미지 생성(e.g. "<sks>의 사진을 만들어줘")
Yo'Chameleon의 이름은 LLaVA의 개인화 버전의 Yo'LLaVA에서 가져왔다고 합니다.
3.1. Representing a Concept as a Learnable Prompt
앞선 연구들에서 prompt tuning은 개인화된 시각적 개념이나 텍스트 기반 생성에서의 시각적 속성 등을 인코딩하는데 효과적이라는 사실이 밝혀졌습니다. 여기서도 학습대상을 LMMs에 맞게 학습 가능한 프롬프트로 변환하였습니다.
"<sks> is <token_1><token_2>...<token_k>."<sks>는 이 개념을 가리키는 학습가능한 식별자이고, <token_i>들은 해당 개념에 대한 시각적 정보들을 인코딩하는 토큰들입니다. 이 구조를 사용하면 전체 프롬프트 중 일부(<token_i>)만 선택해서 업데이트할 수 있어 계산 효율을 높여줍니다.
원래 모델인 Chameleon을 보면, 이미지가 작은 이미지 토큰들로 나누어져 <soi>(start-of-image)와 <eoi>(end-of-image)로 감싸진다는 것을 알 수 있습니다. 최적화 방식은 그대로 auto-regressive*를 사용하며, instruction(질문) - response(답변) 쌍을 학습에 사용합니다. 이 경우, 손실 함수를 계산할 때는 instruction을 빼고 계산합니다. (질문, 답변) 대화 쌍 $(X^i_q, X^i_a)$이 주어졌을 때, 길이 L의 대화에 대한 손실함수는 아래와 같습니다.
*auto-regressive : 이전 단계들의 값들을 기반으로 현재 단계를 추론하는 방식
$p(\mathbf{X}_a) = \prod_{j=1}^{L} p_{\theta}(x_j \mid \mathbf{X}_{a,<j}) \quad (1)$
$\theta$는 <sks>, <token_i>들을 포함한 학습 가능한 매개변수들입니다. 앞서 언급했듯이 instuction에 해당하는 $X_q^i$는 제외하고 계산한 것을 볼 수 있습니다.
3.2. Personalizing Image Generation
Soft prompt를 학습시킬 때 몇 개의 positive image만을 이용하면 최적의 결과를 만들 수 없습니다. 대부분의 연구에서는 크게 두 가지 방법을 사용합니다.
- Data augmentation : 기존의 데이터들을 기반으로 유사한 데이터를 만들어냄
- Hard-negative sample : query와 관련은 없지만(negative image), 매우 유사해 보이는 이미지를 만들어냄
본 연구는 두 번째 방법을 응용하기로 했습니다. 대신 hard-negative image를 부정적인 예시로서 사용하는 것이 아닌, soft-positive image로서 사용한다는 차이가 있습니다. $N$개의 negative image가 있을 때, 모델은 이들을 positive image들의 평균 feature와 유사한 순으로 나열합니다. 그리고 순서대로 (k-1)개 그룹으로 나누어 순위를 부여합니다(<token_k>까지 포함하는 이미지는 번째는 그냥 positive image이기 때문에). 이제 여기에 adaptive token allocation 전략을 적용하여, 순위가 높은 이미지일수록 학습 가능한 토큰을 더 많이 배정합니다. 오직 정확한 positive image에만 전체 토큰들을 배정하기 때문에, 모델은 soft-positive image들로부터 유사한 특징을 배우면서도 positive image만의 정확한 특징도 학습할 수 있습니다([그림 3] 참고).
3.3. Personalizing Image and Language Generation
Yo'LLaVA와 같은 방식으로 아래 두 종류로 이루어진 학습 데이터셋을 만들었습니다.
- Recognition data : 몇 개의 positive image + 100개의 easy-negative image + 100개의 hard-negative image
- Question-answering data : 10개의 질문 + GPT-4o를 통해 생성한 positive image에 대한 응답
앞서 말했듯 단순히 두 개의 작업에 대한 데이터들을 한 번에 학습시킨 토큰은 그 학습 효과가 좋지 못합니다([그림 4] 참고). 때문에, 본 연구는 두 개의 연속된 토큰을 사용하기로 했습니다.
<sks> is <g-tokens><u-tokens>.<g-tokens>와 <u-tokens>는 각각 생성과 이해 작업을 위한 k개와 h개의 학습 가능한 토큰들을 나타냅니다. 학습과정에서 모델은 데이터에 대해 어떤 종류의 토큰이 사용될 지 예측하게 되는데, 이를 self-prompting이라고 명명하였습니다.

[그림 5]를 예시로 들자면, 이해 작업에 해당되는 질문이 들어올 때 출력은 응답 앞에 <u-tokens>을 먼저 붙이게 됩니다. 반대로 생성 작업이라면 응답 앞에 <g-tokens>를 붙입니다. 이렇게 학습시키면 실제 질문이 들어올 때도 모델은 응답 앞에 <u-tokens> 혹은 <g-tokens> 중 하나를 선택하여 붙이게 됩니다.
이는 ToolkenGPT의 multi token 방식을 차용한 것이지만, 다른 점도 있습니다. ToolkenGPT은 토큰들이 작업의 종류를 결정하는 역할만 하지만, Yo'Chameleon에서는 작업에 필요한 실질적인 정보도 포함하고 있다는 점입니다.
4. Experiments
Training
- input image ($n$) : 4
- learnable tokens ($k=|<g\_tokens>|, h=|<u\_tokens>|$) : 16
- optimizer : AdamW
- learning rate : 1e-4
- epoch : 15
- metric : recognition accuracy, generation quality(CLIP similarity)
- GPU : A100 × ?
- batch size : 4
Baselines
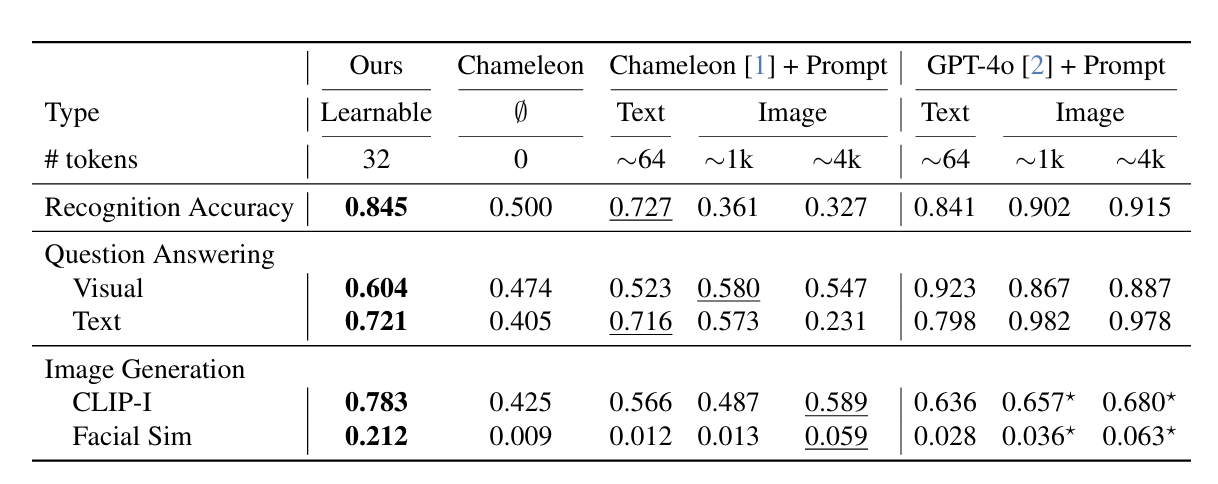
개인화된 텍스트와 이미지 프롬프트를 이용한 Chameleon모델을 baseline으로 했습니다. 학습시킬 개념에 대한 텍스트 프롬프트는 GPT-4o로 그 이미지에 대한 캡션을 생성하여 Chameleon의 시스템 프롬프트에 집어 넣었습니다. 이미지 프롬프트는 그 이미지를 주석과 함께 집어 넣었습니다.
| 텍스트 프롬프트 | "<sks> is a cinnamon-colored Shiba Inu with ..." |
| 이미지 프롬프트 | "This is a photo of <sks><image>" |
또한 Chameleon 말고도 GPT-4o 또한 동일한 텍스트 및 이미지 프롬프트 상에서 baseline으로 사용해 보았습니다.
Dataset
Positive image : Yo'LLaVA
Negative image : LAION-5B (1,000 negative + 100 easy-negative)
Metrics
- 이미지 이해 & 텍스트 생성 : 예/아니오 질문인 "Is <sks> in this photo?"와 다지선다 문제 (Weighted Accuracy Metric)
- 이미지 생성 : "A photo of <sks>"를 이용한 이미지 생성 (CLIP Image Similarity Score)
4.1. Personalized Language Generation
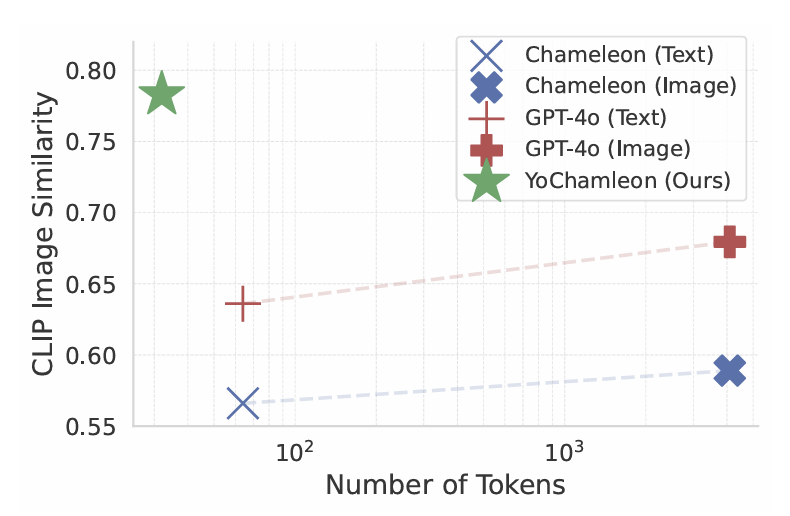
질의 응답 작업의 경우 GPT-4o가 더 뛰어난 성능을 보이는데, 이는 base model인 Chameleon의 성능이 상대적으로 좋지 않았거나, 데이터셋으로 사용한 질문들이 비교적 단순했던 것이 원인으로 보입니다.
4.2. Personalized Image Generation

5. Ablation studies
5.1. Importance of "soft positive" images
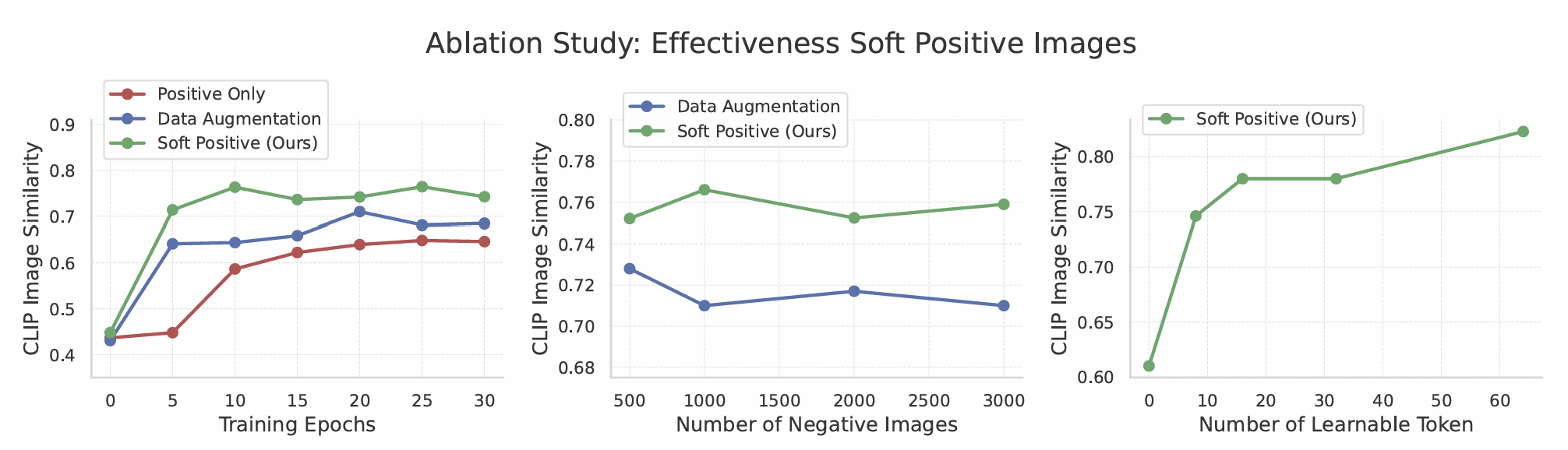
아래 세 가지 경우로 나누어 비교합니다.
- Positive only (2 - 3 images)
- Data augmentation (1000 images)
- Soft Positive Images (1100 images, ours)
5.2. Number of augmented "soft-positive" images
이미지의 수와 관계 없이 soft positive 기법의 성능이 더 뛰어나다는 것을 알 수 있습니다.
5.3. Number of learnable tokens
토큰의 수를 0 - 64 사이로 바꿔가며 측정하였습니다.
5.4. Different training strategies
각 작업들을 위해 분리된 토큰 구조가 효과적인지 판단하기 위해 두 작업에 모두 사용되는 공유 토큰을 사용하는 버전을 만들어 비교해 보았습니다. [표 2]에서 보듯, 공유 토큰을 사용하는 버전은 특정 작업에서 뛰어난 성능을 보이지만, 여러 가지 작업에서 모두 그러지는 못함을 보였습니다. 또한, 이미지 생성 작업에서는 soft-positive 방식의 이미지 생성이 효과적임을 확인했습니다.
분리된 토큰 구조에서도 각기 다른 버전을 만들어 비교해 보았습니다.
- Concatenate : 두 토큰을 작업에 따라 따로 학습시키고 평가 단계에서 서로 합치기
- Concatenate + Finetune : 합치기 단계 이후 추가적인 finetuning
- Self-prompting : 예측 전 어떤 토큰을 사용할 것인지 예측

6. Conclusion
본 연구는 LMMs을 시각 및 텍스트 관련 작업에 대해 개인화하는 작업을 최초로 시도해 보았습니다. 이중 접두사 토큰과 self-prompting 방식을 이용하여 이해 작업과 생성 작업의 성능을 모두 향상시키는데 성공했고, 새로운 soft-positive 학습 전략을 만들어 모델의 본래 성능을 지키면서 개인화 성능도 성공적으로 향상했음을 보여주었습니다.