2023 NeurIPS에 투고된 논문으로, VLM(Vision-Language Model)중 뛰어난 성능을 보인 모델인 LLaVA에 대한 논문입니다.
두 가지 버전이 있는데, 원본 버전인 LLaVA를 기준으로 합니다.
LLaVA
Based on the COCO dataset, we interact with language-only GPT-4, and collect 158K unique language-image instruction-following samples in total, including 58K in conversations, 23K in detailed description, and 77k in complex reasoning, respectively. Please
llava-vl.github.io
1. Introduction
기존의 vision-language 모델들은 각 작업을 하나의 거대한 비전 모델중 하나가 도맡아 해결하며, 언어는 입력 이미지를 묘사하는작업에만 사용하였습니다. 이로 인해 모델들은 대체로 고정된 인터페이스를 가지며, 사용자의 다양한 지시를 반영하지 못한다는 한계점이 있었습니다.
반면 LLM은 보다 폭넓은 작업들을 수행할 수 있습니다. LLM은 사용자의 지시를 언어형식으로 바꾸어서(입력 지시가 언어가 아닐 경우도 있으므로) 원하는 작업으로 전환하여 해결할 수 있도록 신경망을 학습시킵니다. 이미 LLaMA, Alpaca, Vicuna, GPT-4-LLM 등의 여러가지 LLM 모델들이 그 성능을 입증해왔습니다.
본 연구는 instruction-tuning을 language-image multimodal 공간에 적용시킨 첫 번째 사례인 visual instruction-tuning모델, Large Language and Vision Assisant(LLaVA)를 소개합니다. 이 모델은 보편적 목적의 시각 보조 도구를 설계하는 기반이 될 수 있습니다.
2. Related work
- Multimodal Instruction-following Agents
- Instruction Tuning
3. GPT-assited Visual Instruction Data Generation
Image-text 데이터와 같은 multimodal 데이터셋은 많이 공유되어 있지만, 지시 중심의 instruction-following 데이터는 생각보다 많지 않습니다. 데이터를 생성하는게 까다롭기도 하고, crowd-sourcing으로 제작하려해도 명확하게 형식이 통일되지 않기 때문입니다. 그리하여 본 연구는 GPT-4 모델을 사용하여 이 multimodal instruction-following 데이터를 생산하기로 하였습니다.

이미지 $X_V$와 그에 대한 캡션 $X_C$가 주어져 있을 때, GPT-4를 통해 이미지와 관련된 질문 $X_q$를 생성하는 것은 간단합니다. 따라서 기존의 image-text 데이터를 아래와 같이 확장시킬 수 있습니다.
Human : Xq Xv<STOP> Assistant : Xc<STOP>이 방식은 만들기 쉽고 비용도 적게 들지만, 질문과 응답 모두에서 다양성과 깊이 있는 추론이 부족하다는 문제가 있습니다.
때문에 본 연구는 데이터셋을 만들 때 GPT-4 모델을 텍스트만 입력값으로 받는 강한 교사(strong teacher)로서 활용하였습니다. 특히 이미지를 visual feature로 변환할 때 아래 두 가지 표현 방식을 사용하였습니다.
- 장면을 묘사하는 Caption
- 물체의 위치를 나타내는 Bounding box
이런 표현 방식은 이미지를 LLM이 받아들일 수 있는 방식으로 변환시키는데 도움이 됩니다. 본 연구는 COCO 데이터셋을 사용하여 세 가지 유형의 instruction-follwoing 데이터를 만들어냈습니다. 처음 몇 가지의 예시는 직접 만들었고, 후에는 GPT-4 생성으로 학습하여 만들어 냈습니다.
- Conversation : 모델은 이미지를 보고 이미지의 내용, 나타나는 물체의 종류나 개수, 동작, 위치 등을 묻는 질문에 대답합니다. 질문은 모두 명확한 답이 있는 경우만 존재합니다.
- Detailed description : 모델은 이미지를 보고 더 자세한 묘사를 서술합니다.
- Complex reasoning : 위의 두 가지 유형은 시각적 내용에 초첨을 두고 있다면 이 유형은 시각적 내용에 기반한 심층적 추론 내용과 관련된 질문을 합니다. 답변은 단계적인 추론 절차를 요구합니다.
4. Visual Instruction Tuning
4.1. Architecture
매개변수 $\phi$를 통해 학습되는 LLM $f_{\phi}(\cdot)$는 Vicuna를 사용했습니다. 해당 모델이 현재 공적으로 사용 가능한 LLM 모델 중에서 instruction following 성능이 가장 뛰어나다고 합니다.
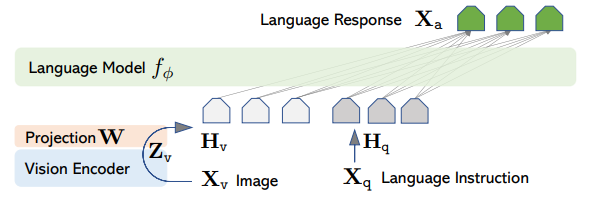
Visual encder는 미리 학습된 CLIP 기반의 ViT-L/14를 사용합니다. 이 모델이 입력 이미지 $X_V$를 visual feature $Z_V$로 변환합니다.
$Z_V = g(X_V)$
Visual feature $Z_V$ 를 LLM이 받을 수 있는 word embedding space상의 값인 $H_V$로 변환할 때는 사영 행렬(projection matrix)$W$로 계산하는 선형 계층을 사용합니다.
$H_V = W \cdot Z_V \quad (1)$
단일 선형 계층 말고도 더 정교한 구조를 설계할 수도 있지만, 이는 LLaVA의 후속 연구로서 남겨두었다고 합니다. => [LLaVA-1.5]
4.2. Training
우선 각 이미지 $X_V$에 대해서 다단계의 대화 데이터(multi-turn conversation data)를 생성합니다.
$(X_q^1, X_a^1, ... , X_q^T, X_a^T)$
이 데이터를 기반으로 단계 t에서의 지시 프롬프트를 정의할 수 있습니다(첫 번째 단계에서만 이미지를 함께 삽입하고, 그 이후부터는 질문만 지시에 반영시킴).
$X_{\text{instruct}}^t =
\begin{cases}
\text{Randomly choose } [X_q^1, X_v] \text{ or } [X_v, X_q^1], & \text{if } t = 1 \\
X_q^t, & \text{if } t > 1
\end{cases} \quad (2)$

이제 이 지시 모음 $X_{instruct}$을 기반으로 auto-regressive 기법을 이용하면 t=i 단계마다 생성되는 token $x_i$를 예측할 수 있습니다.
$p(X_a \mid X_v, X_{\text{instruct}}) = \prod_{i=1}^{L} p_\theta \left(x_i \mid X_v, X_{\text{instruct}, <i}, X_{a, <i} \right) \quad (3)$
여기서 $\theta$는 학습할 매개변수(=$W$), $X_{\text{instruct}$와 $X_{a, <i}$는 단계 t=i 이전의 모든 질문 및 응답들을 나타냅니다. 이제 LLaVA를 학습시켜야 하는데, 학습 단계는 또 두 가지 단계로 나누어집니다.
4.2.1. Pre-training for Feature Alignment
CC3M 데이터셋에서 595K 만큼의 image-text 데이터를 선별하고, 이를 기반으로 instruction-following 데이터를 생성합니다(3절참고). 각 데이터는 단일단계 대화로 간주됩니다. [식 2]를 수행할 때 $X_V$와 $X_q$는 "이미지에 대해 대략적인 설명을 요구"하는 지시중에서 무작위로 선정되며, $X_a$는 해당 이미지의 ground-truth caption을 사용합니다. 학습은 visual encoder와 LLM 제외하고 [식 3]의 likelihood를 최대화하는 방향으로 진행되며, 학습하는 매개변수 $\theta$는 선형 사영 행렬인 $W$가 됩니다.
4.2.2. Fine-tuning End-to-End
두 번째 단계에서는 visual encoder는 그대로 두고 사영 계층과 LLM을 학습시킵니다($\theta = {W, \phi}$). 특히 아래 두 가지 시나리오를 중심으로 학습이 진행됩니다.
- Multimodal Chatbot : 3절에서 생성한 세 종류 유형의 지시에 대한 대화를 생성합니다. 그 중 conversation은 다단계 대화, 나머지 두 개 유형(detailed description, complex reasoning)은 단일 단계 대화로서 작용합니다.
- ScienceQA : ScienceQA 벤치마크를 사용해 선다형 문제를 해결합니다. 단일 단계 대화로서 작용합니다.
5. Experiments
| 1st stage | 2nd stage | |
| GPU | A100 ⨉ 8 | |
| dataset | CC-595K | LLaVA-Instruct-158K |
| epoch | 1 | 3 |
| learning rate | 2e-3 | 2e-5 |
| batch size | 128 | 32 |
5.1. Multimodal Chatbot
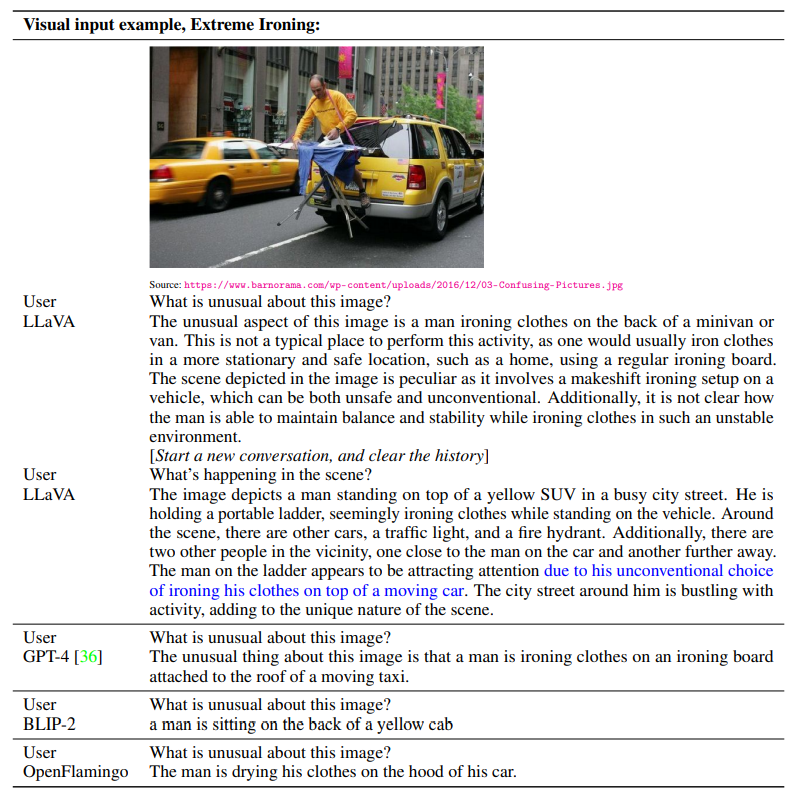
GPT-4 논문에서와 같은 실험조건으로 진행되었습니다. LLaVA가 비교적 적은 이미지 종류를 사용했음에도 더 좋은 성능을 보입니다.
5.1.1. Quantitative Evaluation
정량적 평가를 위해 GPT-4를 평가자로 사용하였습니다. 우선 각 데이터를 (이미지, ground-truth 이미지 묘사 텍스트, 질문) 형태의 triplet으로 만들었습니다. GPT-4에게는 텍스트와 질문, LLaVA에세는 이미지와 질문을 주어 각각 응답을 생성시켰습니다. 이후 GPT-4가 각 응답에 대해 네 가지 기준을 통해(helpfulness / relevance / accuracy / level of detail) 1 - 10 사이의 점수를 부여하게 됩니다. 평가에 사용된 벤치마크는 크게 두 종류가 있습니다.
5.1.2. LLaVA-Bench (COCO)
COCO-Val-2014 데이터셋에서 무작위로 30개 이미지를 선택하여, 각 이미지당 세 유형의 질문(3절)을 생성합니다.

5.1.3. LLaVA-Bench (In-the-Wild)
더 어려운 과제를 위해 다양한 실내/외의 장면, 그림, meme, 스케치 등 24개 이미지에 대한 60개의 질문으로 구성되어 있습니다.

5.1.4. Limitations
LLaVA-Bench (In-the-Wild)는 모델의 약점을 파악하기 위해 의도적으로 어렵게 만든 데이터셋이어서, 몇 개의 문제에 대해 LLaVA가 적절한 답을 하지 못하는 경우가 있었습니다.

5.2. ScienceQA
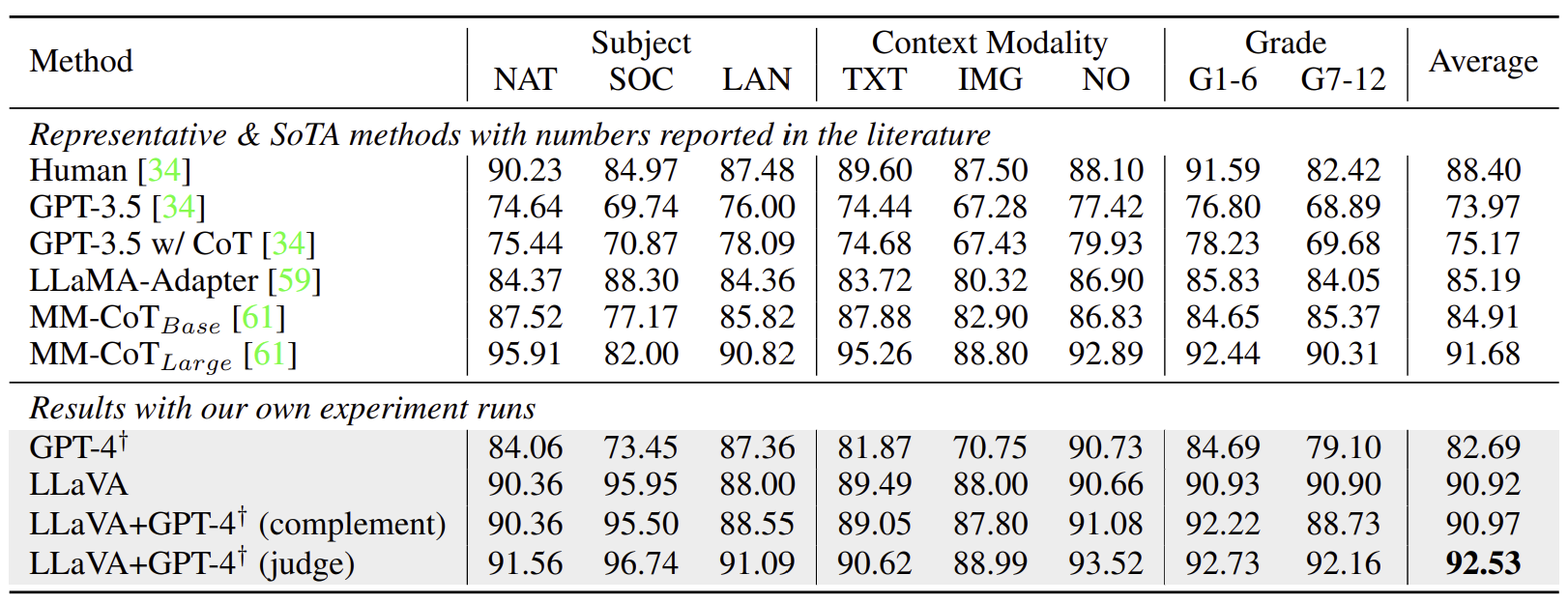
ScienceQA는 21K multimodal 문제들을 가지고 있습니다. 이에 대해 GPT-3.5(chain-of-thought 포함/미포함 두 경우 모두)와 LLaMA-Adapter(chain-of-thought 포함)를 비교군으로 활용하였습니다.
일반 LLaVA 말고도 GPT-4를 함께 사용한 모델 두 가지도 함께 비교하였습니다. GPT-4 complement는 GPT-4가 정답을 맞히지 못할 때마다 LLaVA의 응답을 사용합니다. GPT-4 judge는 GPT-4와 LLaVA가 서로 다른 응답을 낼 때마다 두 응답을 기반으로 하여 GPT-4가 다시 응답을 내도록 합니다. 이 경우 새로운 SotA 성능을 보였는데, GPT-4를 앙상블 학습에 사용한 첫 번째 시도이기도 합니다.
5.2.1. Ablations
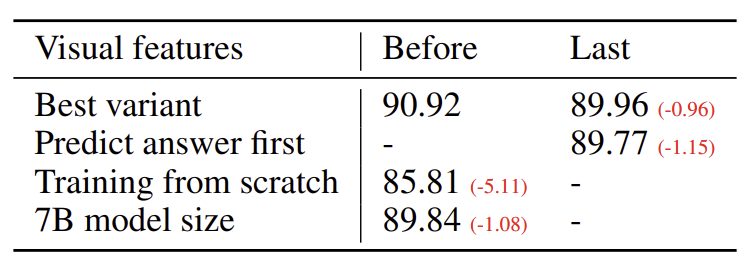
- Visual features : CLIP의 마지막 계층을 visual feature로서 사용해보았습니다. 마지막에서 한 단계 전의 계층을 사용할 때보다 성능이 낮아졌는데, 이는 마지막 계층은 보다 추상적이고 포괄적인 이미지 속성에 대한 feature를 반환하기 때문인 것으로 보입니다.
- Chain-of-thought : 같은 정확도(89.77%)에 도달하는데 정답 우선 방식의 응답을 했을 때는 12epoch, 추론 우선 방식의 응답을 했을 때는 6 epoch이 소모되었습니다. 하지만 epoch을 늘린다고 정확도가 더 올라가지는 않았습니다.
- Pre-training : pre-training을 건너뛰고 바로 scienceQA를 학습시켰을 때 정확도가 감소했습니다.
- Model size : 13B 크기의 모델을 7B로 줄여보았습니다. 이 때도 정확도가 감소함을 확인했습니다.
6. Conclusion
본 연구에서는 language-image instruction-following 데이터를 생성할 수 있는 파이프라인을 제시했고, visual instruction tuning의 효율성을 입증했습니다. LLaVA는 새로운 SoTA 성능을 보여주었으며, multimodal instruction-follwing에 대한 새로운 벤치마크도 제공해주었습니다.