2024 ICLR 포스터 세션에서 발표된 논문입니다.
Minigpt-4
The recent GPT-4 has demonstrated extraordinary multi-modal abilities, such as directly generating websites from handwritten text and identifying humorous elements within images. These features are rarely observed in previous vision-language models. We bel
minigpt-4.github.io
1. Introduction
최근 GPT-4가 공개되면서 vision-language 분야와 관련된 다양한 기능과 작업 능력을 보여주었습니다. GPT-4는 굉장히 놀라운 성능을 보였지만, 모델의 기법들은 여전히 베일에 싸여 있습니다. 지금은 발달된 LLM이 주된 요소로 생각되고 있는데, 그 정도 수준의 LLM이 가진 새로운 기능들은 비교적 작은 모델에서 찾아보기도 힘듭니다.
본 연구에서는 새로운 vision-language 모델인 MiniGPT-4를 소개합니다. 이는 LLaMA 기반의 LLM인 Vicuna를 활용하였으며, ChatGPT와 비교하여 90% 정도의 성능을 달성했다고 합니다. Visual perception 작업에 대해서는, BLIP-2 모델의 vision compoenents를 가져왔습니다(Vit-G/14 + Q-Former). MiniGPT-4는 하나의 사영계층(projection layer)를 사용하여 visual feature를 Vicuna의 입력값에 맞게 변환하고, 그 외 모든 시각/언어 관련 요소들은 고정시킵니다. 학습은 아래 조건으로 진행되었습니다.
- steps : 20k
- batch size : 256
- GPU : A100 ⨉ 4
- time : 10h
- dataset : LAION, Conceptual Captions, SBU
하지만 이것도 데이터의 noise 때문에 모델이 오작동할 가능성이 있다고 합니다. 따라서 3500개의 이미지-텍스트 데이터와 함께 별도로 설계한 대화 형식을 넣어 finetuning을 진행하였습니다.
본 연구의 실험을 통해 MiniGPT-4가 GPT-4와 유사한 성능의 작업을 수행할 수 있음을 보였습니다(e.g. 손글씨 텍스트 추출, 이미지에서 이상현상 묘사 등). 추가로, GPT-4에서는 보여주지 않았던 다른 흥미로운 기능들도 수행했다고 합니다(e.g. 요리하는 사진에서 바로 레시피 생성, 이미지 기반으로 이야기 또는 시 창작 등). 이런 작업들은 이전의 vision-language 모델인 Kosmos-1이나 BLIP-2에서는 보이지 못한 기능입니다.

2. Related works
- Large Language Models (LLMs)
- Leveraging Pre-trained LLMs in Vision-Language Tasks
3. Method
MiniGPT-4는 vision encoder에서 얻어진 시각 정보를 LLM에 맞게 정렬하는 것을 목표로 합니다. 사용한 모델들은 다음과 같습니다.
| Language decoder | Vicuna (LLaMA 기반) |
| Visual encoder | BLIP-2, ViT Backbone, Q-Former |
여기에 더해서, MiniGPT-4는 2-단계 학습 기법을 사용하였습니다. 첫 단계에서는 대규모의 image-text 데이터를 학습하여 기본적인 vision-language 지식을 쌓고, 다음 단계에서 작지만 수준 높은 image-text 데이터를 지정한 대화 형식(template)과 함께 학습하여 가독성 등을 향상시켰습니다.
3.1. First Pretraining Stage
첫 번째 단계는 대규모의 image-text 데이터를 학습하여 기본적인 vision-language 지식을 습득하도록 설계됩니다. 여기서 사용되는 사영계층(projection layer)의 출력값은 LLM의 약한 프롬프트(soft prompt)로 생각하여, LLM이 해당 이미지에 맞는 답(ground-truth text)을 생성하도록 유도합니다.
첫 번째 단계의 LLM 출력값은 오류를 발생시키기도 합니다. 예를 들어 반복되는 단어나 문장이 생성되거나 관계 없는 내용을 서술하는 식입니다. 이는 GPT-3 모델에서도 종종 발생했는데, 이 경우 지시 내용에 대한 finetuning과 인간 피드백을 기반한 강화학습 절차를 거져 GPT-3.5로 개선한 사례가 있습니다. 때문에 MiniGPT-4도 지금 단계에서 개선될 여지가 있습니다.
3.2. Curating a Hight-Quality Alignment Dataset for Vision-Language Domain
두 번째 단계에서 필요한 vision-language domain의 데이터셋은 구하기가 어렵습니다. 때문에 본 연구에서는 직접 finetuning을 위한 이미지 묘사 데이터셋을 만들었습니다.
3.2.1. Initial alinged image-text generation
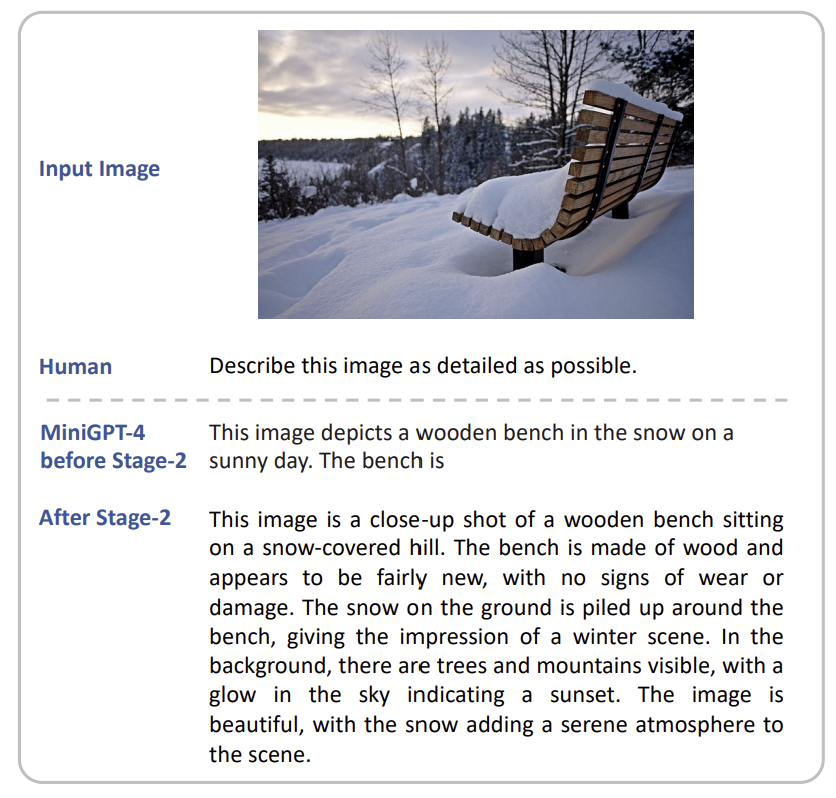
먼저 첫 단계에서 학습한 모델을 사용해 이미지에 대한 설명 텍스트를 생성합니다. 여기서 좀 더 자세한 설명 생성을 위해, 대화 형식을 프롬프트에서 지정해줍니다. 아래 예시에서의 <ImageFeature>는 선형사영계층의 출력값을 나타냅니다.
###Human: <Img><ImageFeature></Img>Describe this image in detail.
Give as many details as possible.
Say everything you see.
###Assistant:문장이 완결되었는지 확인하기 위해서, 문장의 토큰 길이가 80을 넘는지 판단합니다. 만약 그렇지 않다면, 아래 프롬프트를 추가하여 실행합니다.
###Human: Continue ###Assistant:3.2.2. Data post-processing
위에서 생성한 이미지에 대한 묘사글은 반복되는 단어나 관계 없는 내용 등의 오류가 섞여있을 수 있습니다. ChatGPT를 이용하여 이를 바로 고치는 프롬프트를 수행합니다.
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not
English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences.
Return directly the results without explanation. Return directly the input paragraph if it is already
correct without explanation.그럼에도 완전히 고쳐지지 않는 오류들에 대해서는 직접 hard-coded rule에 기반하여 제거 또는 수정합니다. 이렇게 5000개의 image-text pair 중에서 3500개의 올바른 생성물을 선별하여 다음 단계 학습에 사용하였습니다.
3.3. Second-stage Finetuning
Finetuning은 아래의 프롬프트 형식을 사용합니다. 여기서 <Instruction>은 "Descibe this image in detail"과 같이 미리 정해둔 지시 모음 중에 무작위로 선별한 지시사항입니다. 물론 image-text간 정렬도는 이미 첫 단계에서 대강 학습했기 때문에, 따로 회귀 손실값을 계산하거나 하지는 않습니다.
###Human: <Img><ImageFeature></Img><Instruction>###Assistant:4. Experiments
4.1. Uncovering Emergent Abilities with MiniGPT-4 Through Qualitative Examples
MiniGPT-4는 이미지의 상세한 묘사(그림 2)나 특정 meme의 유머적 요소를 언급하는 등(그림 4) 발달된 작업을 수행할 수 있습니다. 이에 대해 대표적인 VLM중 하나인 BLIP-2와 정성적 비교를 시도하였습니다.


4.2. Quantitative Analysis
4.2.1. Advanced Abilities
정량적 분석에서는 아래 네 가지 작업을 수행하도록 하여 사람들에게 출력 결과에 대한 선호도를 조사하였습니다.
| Task | Prompt |
| Meme 분석 | Explain why this meme is funny |
| 레시피 생성 | How should I make something like this? |
| 광고 생성 | Help me draft a professional advertisement for this. |
| 시 작성 | Can you craft a beautiful poem about this image? |
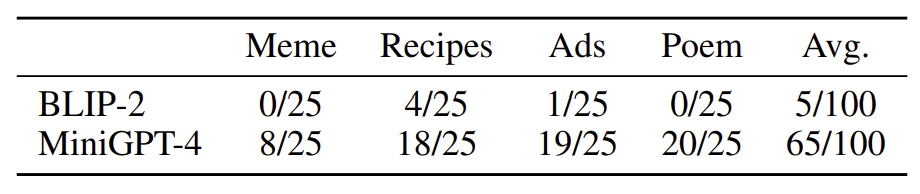
4.2.2. Image Captioning
Image captioning에 대해서는 COCO caption 벤치마크를 이용하여 BLIP-2와 비교하였습니다. MiniGPT-4는 풍부한 시각 정보를 표현하기 때문에, 기존의 image-caption 평가 지표로 평가하기에는 적절하지 않습니다. 때문에 생성한 캡션이 기존 정답 캡션의 정보를 모두 포함하는지를 평가 지표로 사용하였습니다.

4.3. Analysis on the second-stage Finetuning
4.3.1. Effectiveness of the second-stage finetuning
두 번째 단계의 효과를 확인하기 위한 정량적 분석으로 아래 두 가지 작업을 수행하였습니다. 두 가지 모두 COCO 데이터셋에서 무작위로 선택한 100개 이미지에 대해 수행되었습니다. 지표는 생성을 실패한 데이터 수를 기준으로 하였습니다.
| Task | Prompt |
| 상세 묘사 | Describe the image in detail |
| 시 작성 | Can you write a beauiful poen about this image? |

4.3.2. Can the original BLIP-2 benefit from the second-stage data?
본 연구에서는 추가로 BLIP-2를 두 번째 단계를 학습하는데 사용한 데이터(3.2절)를 이용해 fintuning 해보기도 했습니다. 이 모델을 BLIP-2 FT라고 명명합니다. 같은 실험을 진행한 결과(그림 4), BLIP-2 FT는 여전히 주어진 작업을 잘 수행하지 못함을 확인했습니다. 이는 BLIP-2가 사용하는 visual model인 FlanT5 XXL이 MiniGPT-4의 Viuna보다 성능이 뛰어나지 않은 것이 그 이유로, VLM 시스템에서 LLM의 성능이 얼마나 영향을 미치는지를 보여줍니다.
4.3.3. Second stage with Localized Narratives
Dataset Localized Narratives는 이미지에 대한 설명과 그 설명에 대한 이미지에서의 위치정보를 함께 포함하는 데이터셋입니다. 본 연구에서는 MiniGPT-4의 두 번째 단계 학습에서 직접 생성한 데이터셋(3.2절) 대신 이 Localized Narratives 데이터셋을 사용해보기도 했습니다. 이 모델을 MiniGPT-4 LocNa라고 명명합니다. 실험 결과(그림 4) MiniGPT-4는 일부 경우에 대해 긴 이미지 묘사를 생성할 수 있는 것으로 보이나, 그 생성 수준이 높지 않고 단조로워보이며, 다른 경우들에 대해서 보편적으로 작용되지도 않는 것으로 보입니다. 이는 Localized Narratives 데이터셋 자체가 단조로운 이미지 묘사를 포함하기 때문인 것으로 보입니다.
4.4. Ablation on the Architecture designs
단일 선형계층이 visual feature를 LLM과 연결하는 데에 효과적인지 확인하기 위하여, 다른 모델 구조들과 비교해보았습니다. 비교군은 아래 세가지 모델입니다.
- (a) Q-Former 제거 (ViT에서 바로 Vicuna와 연결)
- (b) 세 개의 선형 계층 (단일 계층 대신)
- (c) Q-Former를 vision module에 대해 추가적으로 fintuning
[표 4]에서 볼 수 있듯 Q-Former를 제거해도 원본과 비교하여 큰 성능의 차이를 보이지 않아, Q-Former가 성능에 중요한 영향을 끼치지 않음을 알 수 있습니다.

4.5. Limitation Analysis
4.5.1. Hallucination
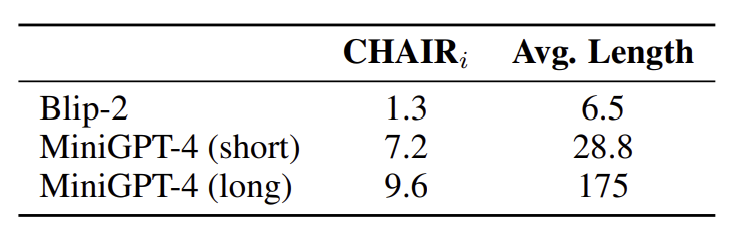
MiniGPT-4는 LLM을 기반으로 하기 때문에, 환각현상과 같은 LLM의 문제점도 똑같이 가지게 됩니다. 이 환각 현상의 빈도를 정확히 측정하기 위해 장문과 단문 응답 두 가지 경우를 나누어 CHAIR 평가지표를 사용해 평가를 수행했습니다.
| Model | Prompt |
| MiniGPT-4 (long) | Please describe this image as detailed as possible |
| MiniGPT-4 (short) | Please describe the image shortly and precisely, in less than 20 words |
[표 5]에서 보이듯이 캡션의 길이가 길어질 수록 환각 현상의 빈도 또한 높아지는 것을 알 수 있습니다. BLIP-2가 훨씬 작은 빈도를 보이긴 하지만, 대신 나타낼 수 있는 묘사의 범위가 더 적습니다(표 2). 이렇게 자세한 묘사에 대한 환각 현상 문제는 아직 명확하게 해결되지 않은 이슈입니다. 어쩌면 AI 피드백 기반의 강화학습이 효과적인 해결방안이 될 수도 있습니다.
4.5.2. Spatial Information Understanding
MiniGPT-4는 공간의 위치 파악에 대해서도 약한 성능을 보입니다. 이는 공간적 위치 정보가 포함된 image-text 데이터가 부족해서 발생하는 문제로 보입니다. 이러한 데이터가 포함된 RefCOCO나 Visual Genome 등으로 학습한다면 해결될 수도 있습니다.

5. Discussion
GPT-4가 뛰어난 vision-language 성능을 보이는 이유는 '이미지에 대한 이해'와 '언어 생성' 두 가지 기술이 적절히 조합되었기 때문입니다. ChatGPT와 Vicuna와 같은 뛰어난 LLM은 이미 사용자의 요구에 맞에 적절한 언어를 생성할 수 있으므로, 이미지에 대한 이해 능력만 갖추게 된다면 동일하게 뛰어난 vision-language 처리를 할 수 있을 것입니다.
모델의 첫 번째 단계에서 MiniGPT-4는 '이미지를 이해'하는 법을 배웁니다. 하지만 여기서는 아직 생성하는 이미지 캡션이 자연스럽지 않습니다. 때문에, 두 번째 단계에서 MiniGPT-4는 '언어를 생성'하는 법을 배웁니다.
모델은 향후 조합적 작업(compositional task)들에 대해 일반화할 수 있고 성능을 높이는 방향으로 개선될 수 있습니다.
'Reveiw > Paper' 카테고리의 다른 글
| [review] Attention Is All You Need (0) | 2025.06.29 |
|---|---|
| [review] Visual Instruction Tuning (0) | 2025.06.26 |
| [review] Improved Baselines withs Visual Instruction Tuning (0) | 2025.06.24 |
| [review] NeRF: Representing Scene as Neural Radiance Fields for View Synthesis (0) | 2025.06.17 |
| [review] DiffusionRig: Learning Personalized Priors for Facial Appearance Editing (0) | 2024.11.19 |