카카오 AI 연구팀에서 진행한 연구로, 2025 CVPR 하이라이트 논문으로 선정되었습니다.
https://arxiv.org/abs/2405.20216
Boost Your Human Image Generation Model via Direct Preference Optimization
Human image generation is a key focus in image synthesis due to its broad applications, but even slight inaccuracies in anatomy, pose, or details can compromise realism. To address these challenges, we explore Direct Preference Optimization (DPO), which tr
arxiv.org

1. Introduction
인물 이미지는 생성 AI 모델의 핵심적인 과제 중 하나입니다. 현재는 확산모델로 이를 어느정도 구현하고 있지만, 아직까지 인체의 구조나 자세 교정에 있어서 조금씩 부정확한 부분이 존재합니다. 이를 교정하기 위해 높은 품질의 이미지로 fine-tuning을 시행한 base model을 만들어도, 여전히 만족스러운 이미지를 만들어내지 못하고 있습니다. 본 연구의 목표는 fine-tuning을 거친 base model을 개선하여 인물 이미지의 품질을 더 올리는 것에 중점을 두었습니다.
본 연구에서 사용한 방법은 Direct Preference Optimization(DPO) 방식입니다. DPO는 LLM Alignment 분야에서 사용되던 방법으로, 하나의 입력에 대해 더 선호되는 이미지(winning image)와 덜 선호되는 이미지(losing image)를 쌍으로 모델을 학습시켜, 덜 선호되는 경향은 피하고 더 선호되는 방향으로 이미지가 생성되도록 유도하는 방식입니다. DPO가 이미지 생성 분야에서도 사용되며 Diffusion-DPO와 같은 모델도 개발되었지만, 이는 AI로 생성된 이미지만을 사용해 학습에 사용되는 이미지 쌍을 구성하기 때문에 모델의 품질이 높지 않다는 문제가 있습니다.
본 연구에서 소개하는 모델인 Human image Generation through DPO(HG-DPO)는 GAN의 작동 방식과 유사하게 생성 결과가 losing image를 닮을수록 감점을, winning image와 닮을수록 가점을 부여하여 학습을 진행합니다.
HG-DPO는 첫 번째 전략으로 실제 이미지를 winning image로, 생성 이미지를 losing image로 사용하는 개선된 DPO (enhance DPO)를 사용하였습니다. 하지만 실제 이미지와 생성 이미지 사이의 차이가 상당히 크기 때문에, 이 방식으로 한 번만에 학습을 시키는 것은 어려웠습니다.
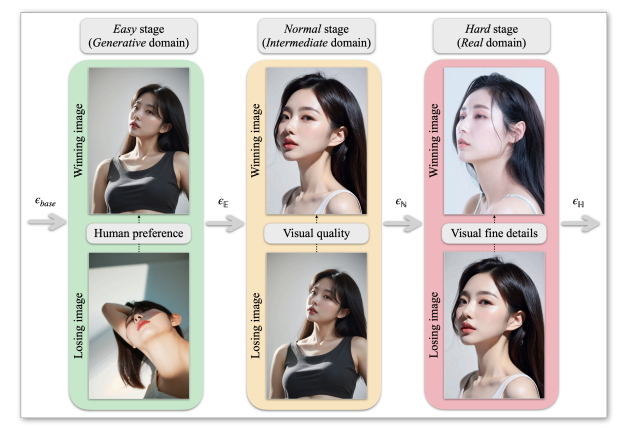
이 간극을 메우기 위해, 두 번째 전략으로 학습을 여러 단계로 나누는 curriculum learning을 도입했습니다. HG-DPO는 세 단계로 나뉘었고, 각 단계마다 서로 다른 종류의 데이터셋을 사용했습니다.
- Easy : 기본적인 인간의 해부학적 특징과 자세를 학습
- Normal : 구체적이고 사실적인 인체 특징 학습
- Hard : 고품질의 미세한 세부 구성요소 학습
각 단계마다 학습 난이도는 높아지며, 이를 통해 HG-DPO는 실제와 비슷한 이미지를 만들어낼 수있게 학습됩니다.
2. Related Work
- Aligning diffusion models with human preferences
- Curriculum Learning
3. HG-DPO
프롬프트 $P$와 실제 이미지 $X_{real}$가 짝지어진 이미지-텍스트 데이터셋 $D_{real} = (P, X_{real})$이 주어져 있을 때, HG-DPO의 목표는 base model인 $\epsilon_{base}$가 $X_{real}$와 유사한 수준의 이미지를 생성해낼 수 있도록 하는 것입니다.
이를 위해 $\epsilon_{base}$는 세 단계의 DPO 학습을 거쳐야 합니다. 각 단계는 winning image로 무엇을 사용하느냐에 따라 그 난이도가 달라집니다. Easy stage는 생성 이미지를 winning image로 사용하지만, Hard stage는 실사 이미지를 winning image로 사용하기 때문에 난이도가 올라가게 됩니다. 각 단계의 losing image는 이전 단계의 winning image를 사용합니다(Easy stage는 이전 단계가 없으니 똑같이 생성 이미지를 사용합니다).
3.1. Easy Stage
Easy stage에서는 기본적으로 사람들에게 선호되는 이미지를 생성하는 방법을 학습합니다. Winning image와 losing image 모두 생성 이미지를 사용합니다. 하지만 winning image는 losing image보다 더 나은 인체 구조와 자세를 가져야 하며, 프롬프트를 더 충실히 구현한 것이어야 합니다. Easy stage에서 $\epsilon_{base}$는 $\epsilon_{\mathbb{E}}$로 개선됩니다.

3.1.1. Image pool generation
프롬프트마다 두 쌍의 이미지만 생성하지 않고, N개의 이미지들(image pool)을 생성할 것입니다. 프롬프트 $p_i \; (i=1, ..., D)$에 해당하는 image pool $\mathcal{X}_{gen}^i$은 다음과 같이 정의됩니다.
\begin{equation}
\mathcal{X}_{\text{gen}}^{i} = \left\{ x_{\text{gen}}^{i_j} \right\}_{j=1}^{N},
\quad
x_{\text{gen}}^{i_j} = \mathcal{G}\left( \epsilon_{\text{base}},\, p^{i},\, r^{i_j} \right).
\end{equation}
※ $\mathcal{G}$ : 무작위 시드 $r^{i_j}$로 작동하는 text-to-image sampler
N개의 이미지를 생성하기 때문에 무작위 시드도 서로 다른 N개가 필요합니다. $\left\{ r^{i_j} \right\}_{j=1}^N$
3.1.2. Selection of winning and losing images
이제 생성한 이미지들에 각각 점수를 부여합니다. 프롬프트 $p^i$를 고려했을 때 $x_{\text{gen}}^{i_j}$의 점수는 다음과 같습니다.
\begin{equation}
\mathcal{S}_{\text{gen}}^{i} = \left\{ s_{\text{gen}}^{i_j} \right\}_{j=1}^{N},
\quad
s_{\text{gen}}^{i_j} = f\!\left( x_{\text{gen}}^{i_j},\, p^{i} \right).
\end{equation}
※ $f$ : human preference estimator인 PickScore
점수를 계산한 뒤, 가장 높은 점수와 가장 낮은 점수를 가지는 두 이미지를 winning image($x_{\mathbb{E}}^{w, i}$)와 losing image($x_{\mathbb{E}}^{l, i}$)로 선발합니다.
\begin{equation}
\left( x_{E}^{w,i},\, x_{E}^{l,i} \right)
=
\left( x_{\text{gen}}^{i}\!\left[ j_{E}^{w} \right], \, x_{\text{gen}}^{i}\!\left[ j_{E}^{l} \right] \right)
\end{equation}
\[
\text{where} \quad
\left( j_{E}^{w},\, j_{E}^{l} \right)
=
\left(
\arg\max_{j_{E}^{w} \in \{1,\ldots,N\}} \mathcal{S}_{\text{gen}}^{i},\,
\arg\min_{j_{E}^{l} \in \{1,\ldots,N\}} \mathcal{S}_{\text{gen}}^{i}
\right).
\]
이제 이를 통해 Easy stage를 위한 데이터셋 $D_{\mathbb{E}}=\left\{ \left( p^i, x_{E}^{w,i},\, x_{E}^{l,i} \right) \right\}$를 만들어낼 수 있습니다.
3.1.3. Statistics matching loss
이 방식을 그대로 사용하면 이미지의 색감이 변하는 color shift artifact가 발생하게 됩니다([그림 8] 참고). 이는 $\epsilon_{base}$와 $\epsilon_{\mathbb{E}}$의 분포가 달라지기 때문입니다. 따라서 분포 차이를 최소로 할 수 있도록 $\epsilon_{\mathbb{E}}$의 목적 함수를 수정해야 합니다. Timestep $t$에서 생성된 winning image의 noisy latent 값을 $l^t$라고 할 때, 이를 이용해 $\epsilon_{base}$와 $\epsilon_{\mathbb{E}}$에서 생성한 이전 단계($t-1$) latent를 $l_{base}^{t-1}$와 $l_{\theta}^{t-1}$라고 합니다. 이 때 수정된 목적 함수는 다음과 같습니다.
\begin{equation}
\mathcal{L}_{\text{stat}} =
\mathbb{E}_{D_{E},\, t \sim \mathcal{U}(0, T)}
\left[
\left\|
\mu\!\left( l_{\theta}^{t-1} \right) - \mu\!\left( l_{\text{base}}^{t-1} \right)
\right\|_{2}^{2}
\right].
\end{equation}
※ $\mu$ :데이터를 채널 축으로 계산했을 때의 평균값
이렇게 계산한 $\mathcal{L}_{stat}$은 기존의 목적 함수에 더해져 보정됩니다. $ \mathcal{L} = \mathcal{L}_{D-DPO} + \lambda_{stat} \mathcal{L}_{stat}$
3.2. Normal Stage
Normal stage에서는 더욱 실사에 가까운 구도와 포즈를 가지는 이미지를 생성하는 방법을 학습합니다. Easy stage와 Hard stage의 중간 단계이기 때문에, winning image는 생성 이미지와 실사 이미지의 중간 단계에 있어야 합니다. 이를 위해 HG-DPO는 중간 단계(intermediate domain)라는 개념을 만들었습니다. Normal stage에서 $\epsilon_{E}$는 $\epsilon_{\mathbb{N}}$로 개선됩니다.
3.2.1. Intermediate domain
중간 단계의 이미지는 실사 이미지에 noise를 더한 뒤, $\epsilon_{\mathbb{E}}$를 이용해 다시 실사 이미지로 재생성하는 방식(SDRecon)으로 만들어집니다. 이렇게 만들어진 이미지는 실사 이미지의 특징을 보존하면서도 자세한 부분은 실제와 닮지 않은, 생성 이미지와 실사 이미지의 중간적인 특징을 가지게 됩니다.
중간 이미지의 정도는 noise가 만들어지는 timestep을 다르게 하여 조절할 수 있습니다. 그래서 서로 다른 timestep의 다양한 중간 이미지를 만들 수 있는데, 프롬프트 $p^i$ 와 그에 대응되는 실사 이미지 $x_{real}^i$이 있을 때, timestep의 집합 $T=\{t_1, t_2, ..., t_T\}$를 사용하여 다음과 같이 정의합니다.
\begin{equation}
\mathcal{X}_{\text{int}}^{i} = \left\{ x_{\text{int}}^{i,t} \right\}_{t \in \mathcal{T}},
\quad
x_{\text{int}}^{i,t} = \mathcal{R}\!\left(
\epsilon_{\text{base}},\, p^{i},\, x_{\text{real}}^{i},\, t
\right).
\end{equation}
※ $\mathcal{R}$ : SDRecon operator
중간 이미지는 $t$가 $t_T$에 가까워질 수록 생성 이미지와 가까워지고, $t_1$에 가까워질 수록 실사 이미지에 가까워집니다.
3.2.2. Selection of winning and losing images
3.1.2.절과 같은 방식으로 각 결과에 대해 점수를 부여합니다.
\begin{equation}
\mathcal{S}_{\text{int}}^{i} = \left\{ s_{\text{ int }}^{i_t} \right\}_{t \in \mathcal{T}},
\quad
s_{\text{gen}}^{i_t} = f\!\left( x_{\text{ int }}^{i_t},\, p^{i} \right).
\end{equation}
이번에는 가장 높은 점수를 가진 이미지만을 선택해 winning image로 사용하고, losing image는 Easy stage에서 사용했던 winning image를 사용합니다.
\begin{equation}
\begin{aligned}
\left( x_{N}^{w,i},\, x_{N}^{l,i} \right)
&=
\left(
x_{\text{int}}^{i}\!\left[ j_{N}^{w} \right],\,
x_{\text{gen}}^{i}\!\left[ j_{N}^{l} \right]
\right), \\
\text{where} \quad
\left( j_{N}^{w},\, j_{N}^{l} \right)
&=
\left(
\arg\max_{j_{N}^{w} \in \mathcal{T}} \mathcal{S}_{\text{int}}^{i},\,
\arg\max_{j_{N}^{l} \in \{1,\ldots,N\}} \mathcal{S}_{\text{gen}}^{i}
\right).
\end{aligned}
\end{equation}
3.2.3. Filtering
데이터셋 $D_{\mathcal{E}}$의 모든 순서쌍이 Noraml stage의 데이터셋으로 변하는 것은 아닙니다. 이 중에서 높은 품질의 데이터만 선택할수 있도록, 3.2.2.절에서의 점수가 $x_{\mathcal{N}}^{1, i}$보다 높은 $i$만 데이터셋에 포함시키게 됩니다.
\begin{equation}
\mathcal{D}_{N}
=
\left\{
\left( p^{i},\, x_{N}^{w,i},\, x_{N}^{l,i} \right)
\right\}_{i \in \mathcal{K}},
\quad
\mathcal{K}
=
\left\{
k \,\middle|\,
S_{\text{int}}^{k}\!\left[ j_{N}^{w} \right]
\ge
S_{\text{gen}}^{k}\!\left[ j_{N}^{l} \right]
\right\}.
\end{equation}
이제 이를 통해 Normal stage를 위한 데이터셋 $D_{\mathbb{N}}=\left\{ \left( p^i, x_{N}^{w,i},\, x_{N}^{l,i} \right) \right\}$를 만들어낼 수 있습니다.
3.3. Hard Stage
Hard stage에서는 실사에 가까운 디테일까지 고려하여 이미지를 생성하는 법을 학습합니다. 앞서 언급해왔던 것 처럼 이 단계에서는 실사 이미지를 winning image로 사용해야 하지만, 실제 실험 결과 중간 단계의 timestep $t_1$에 해당하는 중간 이미지(실사 이미지와 제일 가까운 중간 이미지)를 사용했을 때 더 좋은 결과가 나온 것을 확인했습니다.
\begin{equation}
\left( x_{H}^{w,i},\, x_{H}^{l,i} \right) = \left( x_{\text{int}}^{i}\!\left[ t_{1} \right],\, x_{N}^{w,i} \right).
\end{equation}
이제 이를 통해 Hard stage를 위한 데이터셋 $D_{\mathbb{H}}= \left\{ \left( p^i, x_{H}^{w,i},\, x_{H}^{l,i} \right) \right\}$를 만들어낼 수 있습니다.
3.4. Training the Text Encoder
이미지-텍스트 정렬을 개선하기 위해 text encoder를 별도로 학습하기도 했습니다. 시각적 품질 향상 보다는 이미지-텍스트 정렬에 중점을 두었기 때문에, text encoder는 Easy stage 까지만 학습 되었습니다.
4. Experimental Settings
4.1. Datasets
데이터셋은 300k 크기의 고품질 사람 이미지로 이루어져 있으며, 그 중 5k 만큼을 testing set으로 사용하였습니다. 생성되는 이미지와 캡션은 LLaVA와 Qwen2-VL을 사용했다고 합니다.
4.2. Metrics
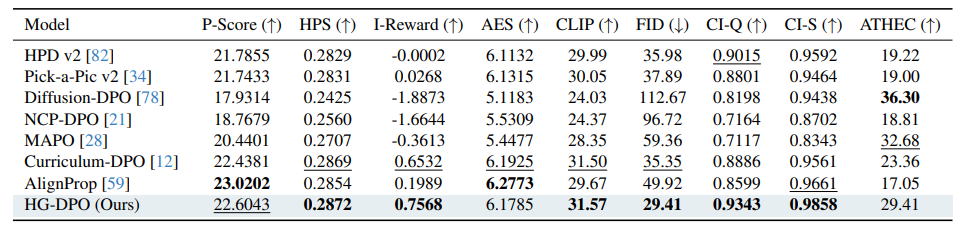
본 연구에서 사용한 지표들은 아래와 같습니다.
| Metric | 평가 요소 |
| PickScore(P-Score) | 프롬프트 중심의 이미지 선호도 |
| HPS-v2(HPS) | 프롬프트 중심의 이미지 선호도 |
| ImageReward(I-Reward) | 프롬프트 중심의 이미지 선호도 |
| AestheticScore(AES) | 프롬프트와 무관한 이미지 선호도 |
| CLIP | 이미지-텍스트 정렬 |
| FID | 실제 이미지와 생성 이미지의 유사도 |
| CI-Q | 이미지 품질 |
| CI-S | 이미지 sharpness |
| ATHEC | 이미지 sharpness |
| ArcFace | identity similarity (T2I) |
| VGGFace | identity similarity (T2I) |
Color shift artifact를 계산하기 위해서는 RGB의 이미지를 HSV로 바꾼 뒤, 색조의 평균을 계산하여 판단합니다.
4.3. Baselines
| Baseline | 비교 목적 |
| HPD v2 | 데이터셋 |
| Pick-a-Pic v2 | 데이터셋 |
| NCP-DPO | 기존 방법의 suboptimality 증명 |
| MAPO | 기존 방법의 suboptimality 증명 |
| Curriculum-DPO | 같은 Curriculum learning이지만 real image를 사용하지 않음 |
| AlignProp | online learning baseline |
5. Analysis on HG-DPO
5.1. Comparison with the Previous Methods