Ludwig Maximilian University of Munich와 Heidelberg University에서 발표한 논문으로, Stable Diffusion으로도 잘 알려진 Latent Diffusion Models에 관한 논문입니다.
https://arxiv.org/abs/2112.10752
High-Resolution Image Synthesis with Latent Diffusion Models
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism t
arxiv.org

Abstract
Diffusion Moedel(DM)은 강력한 생성 모델입니다. 하지만 pixel space에서 계산이 진행되기 때문에 상당한 양의 GPU 자원을 소모해야 한다는 단점이 있습니다. 때문에 본 연구는 latent space를 도입한 Latent Diffusion Model(LDM)을 제시합니다. LDM은 DM의 정확성은 유지하면서 단점이었던 복잡성을 극복하여 강력한 생성모델임 증명해냈습니다.
1. Introduction
1.1. Democratizing High-Resolution Image Synthesis
DM은 기본적으로 likelihood 기반 모델입니다. Likelihood 기반 모델의 공통된 문제점은 우리가 쉽게 알아차릴 수 없는 세부사항까지 계산하는데 상당한 시간을 소모한다는 것입니다. DM에서는 이 문제를 해결하기 위해 학습 단계에서 표본 자체를 적게 선택하는 undersampling 방식을 사용하지만, 그럼에도 근본적인 해결책을 찾지는 못했습니다. 그 수가 적어도, 표본마다 학습과정에서 손실 함수에 대한 계산 및 최적화를 많이 해야 하기 때문입니다.
1.2. Departure to Latent Space
Likelihood 기반 모델들은 크게 학습 단계가 두 가지로 나뉩니다.
- 세부적인 특징(high-frequency details)만을 제거하는 지각적 압축(perceptual compression)
- 실제 의미적인 요소(사람의 위치나 구도 등)를 학습하는 의미적 압축(semantic compression)
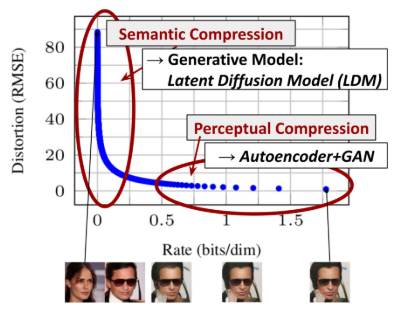
[그림2] 는 각 학습 모델의 rate-distortion trade-off(압축 비율 - 왜곡 사이의 반비례)를 보여줍니다. Autoencdoer+GAN의 경우를 보면 자세한 묘사는 생략되지만 전체적으로 왜곡되는 값은 크지 않다는 것을 알 수 있습니다(지각적 압축). 그 다음, 모델은 데이터의 의미적 구성과 개념을 이해합니다(의미적 압축). 본 연구에서는 학습시간이 많이 걸리는 지각적 압축 부분을 집중합니다. LDM은 autoencoder를 학습시켜 pixel space와 지각적으로는 동일하지만 더 저차원의 공간인 latent space를 만들 수 있게 하고, 이 공간 안에서 DM을 학습하게 됩니다.
LDM의 중요한 점 중 하나는 autoencoding을 한 번 학습하면 다른 종류의 DM에서도 동일하게 활용할 수 있다는 것입니다. 또한 Transformer를 추가하면 token 기반의 모델에도 적용시킬 수 있습니다 (3.3절 참고).
2. Related works
- Generative Models for Image Synthesis
- Diffusion Probabilistic Model (DDPM)
- Two-Stage Image Synthesis
3. Method
1절에서 언급했듯이, peceptual compression에서 소비되는 자원을 줄이기 위해 autoencoder를 이용하여 해당 단계를 분리하는 작업을 진행합니다. 이 방법을 이용하면 크게 세 가지 이점이 있습니다.
- 학습 표본이 더 낮은 차원에서 추출되기 때문에 더 효율적으로 계산할 수 있다
- UNet 구조에서 학습된 편향값을 다음 학습 및 추론 과정에서 유용하게 사용할 수 있다
- 한 번 학습한 autoencoder모델을 다른 생성 모델에서도 사용할 수 있다
3.1. Perceptual Image Compression
Perceptual compression은 이전 연구들과 동일하게 pixel space에서 계산하는 L1 / L2 loss를 사용합니다. 이 방법을 사용하면 모델을 통해 생성되는 값을 이미지 변형(image manifold)의 형태 내에서 제한시킬 수 있습니다.
만약 입력 이미지가 $x \in \mathbb{R}^{H \times W \times 3}$라면(3은 RGB 채널), encoder $\mathcal{E}$ 가 $x$를 latent space상의 값 $z \in \mathbb{R}^{h \times w \times c}$로 변환시킵니다.
$z = \mathcal{E}(x)$
Latent space에서의 계산이 모두 끝나면, decoder $\mathcal{D}$는 $z$를 다시 원래 공간의 값인 $\tilde{x}$ 복구시킵니다.
$\tilde{x} = \mathcal{D}(z) = \mathcal{D}(\mathcal{E}(x))$
여기서 latent space에 의해 크기가 압축되는 비율을 downsapling factor $f = H/h = W/w$로 정의합니다. Downsampling factor는 $f=2^m, \quad m \in \mathbb{N}$단위로 설정했습니다.
Latent space의 분산이 높아지는 것을 방지하기 위해 본 연구에서는 두 가지 정규화 방법을 사용해보았습니다.
- KL-reg. : latent space가 표준 정규분포를 따르도록 약한 KL-penalty를 부여함
- VQ-reg. : 벡터 양자화를 decoder에 적용
여기에다 1차원으로만 변환되는 기존의 latent space 모델과 달리 LDM은 latent space에서도 2차원의 구조를 그대로 유지하고 있기에 적은 압축으로도 뛰어난 계산 성능을 보여준다고 말합니다.
3.2. Latent Diffusion Models
3.2.1. Diffusion Models
$L_{DM} = \mathbb{E}_{x, \epsilon \sim \mathcal{N}(0,1), t} \left[ \left\| \epsilon - \epsilon_\theta(x_t, t) \right\|_2^2 \right]
\quad (1)$
3.2.2. Generative Modeling of Latent Representations
이제 latent space를 적용하면 의미상으로 중요한 정보(hight-frequency를 제외하고)에만 집중할 수 있고, 계산이 더 빠른 차원에서 학습을 진행할 수 있습니다.
$L_{LDM} := \mathbb{E}_{\mathcal{E}(x), \epsilon \sim \mathcal{N}(0,1), t} \left[ \left\| \epsilon - \epsilon_\theta(z_t, t) \right\|_2^2 \right] \quad (2)$
여기서 $\epsilon_\theta(\circ, t)$는 time-conditional UNet입니다. Forward process는 DM과 똑같기 때문에, 여기서는 encoder를 통해 간단하게 $z_t$를 뽑아내기만 하면 됩니다.

3.3. Conditioning Mechanisms
다른 DM 모델처럼 condition은 $p(z|y)$의 형식으로 지정해주면 됩니다. 좀더 자세하게 풀어보면 아래 두 가지가 추가됩니다.
- autoencoder의 형식 $\epsilon_\theta (z_t, t, y)$
- 조건 y(텍스트, 이미지 등)를 적절한 값으로 변환시켜 주는 domain specific encoder $\tau_\theta (y) \in \mathbb{R}^{M \times d_\tau}$
본 연구는 다양한 입력값들을 더 잘 받기 위해 여기에 더해서 UNet에 cross-attention을 추가하였습니다.
$Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d}}) \cdot V, \quad with$
$Q = W_Q^{(i)} \cdot \varphi_i(z_t), \quad K = W_K^{(i)} \cdot \tau_\theta(y), \quad V = W_V^{(i)} \cdot \tau_\theta(y)$
- $ \varphi_i(z_t) \in \mathbb{R}^{N \times d_{\epsilon}^i}$ : $\epsilon_{\theta}$의 중간값
- $W_V^{(i)} \in \mathbb{R}^{d \times d_{\epsilon}^i}, \quad W_Q^{(i)} \in \mathbb{R}^{d \times d_{\tau}}, \quad W_K^{(i)} \in \mathbb{R}^{d \times d_{\tau}} $ : 학습시킬 가중치들
다시, conditioning을 적용하면 objective function을 다음과 같이 정의할 수 있습니다.
$L_{LDM} := \mathbb{E}_{\mathcal{E}(x), y, \epsilon \sim \mathcal{N}(0,1), t} \left[ \left\| \epsilon - \epsilon_\theta(z_t, t, \tau_\theta(y)) \right\|_2^2 \right] \quad (3)$
4. Experiments

4.1. On Perceptual Compression Tradeoffs
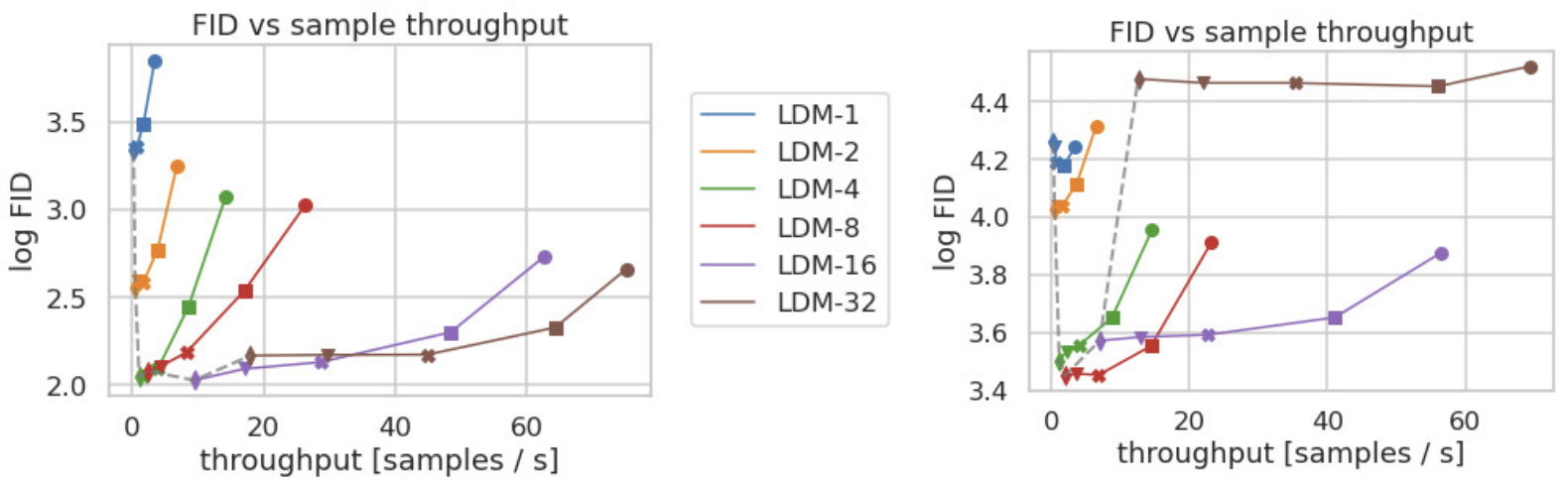
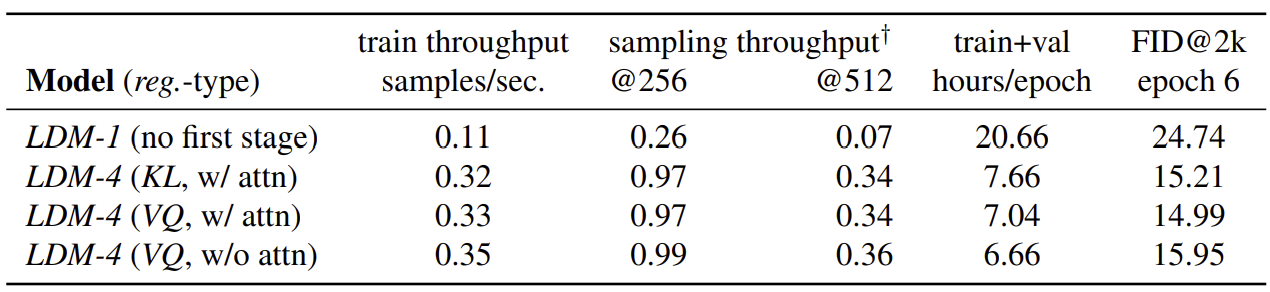
Downsampling의 크기에 따라 $LDM-f \quad (f \in {1, 2, 4, 8, 16, 32})$를 비교합니다. [그림 6]에서 볼 수 있듯, f가 작으면 (1 - 2) 학습 시간이 오래 걸림을 알 수 있습니다. 반대로 f가 크면 ( - 32) 생성 성능 자체가 떨어지게 됩니다.


[그림 7]에서는 sampling 속도에 따른 FID 점수를 비교하였습니다. Throughput(클수록 좋음)에 대한 FID값(낮을수록 좋음)을 고려하면, 여기에서도 LDM-{4 - 8} 정도에서 제일 뛰어난 성능을 보입니다.
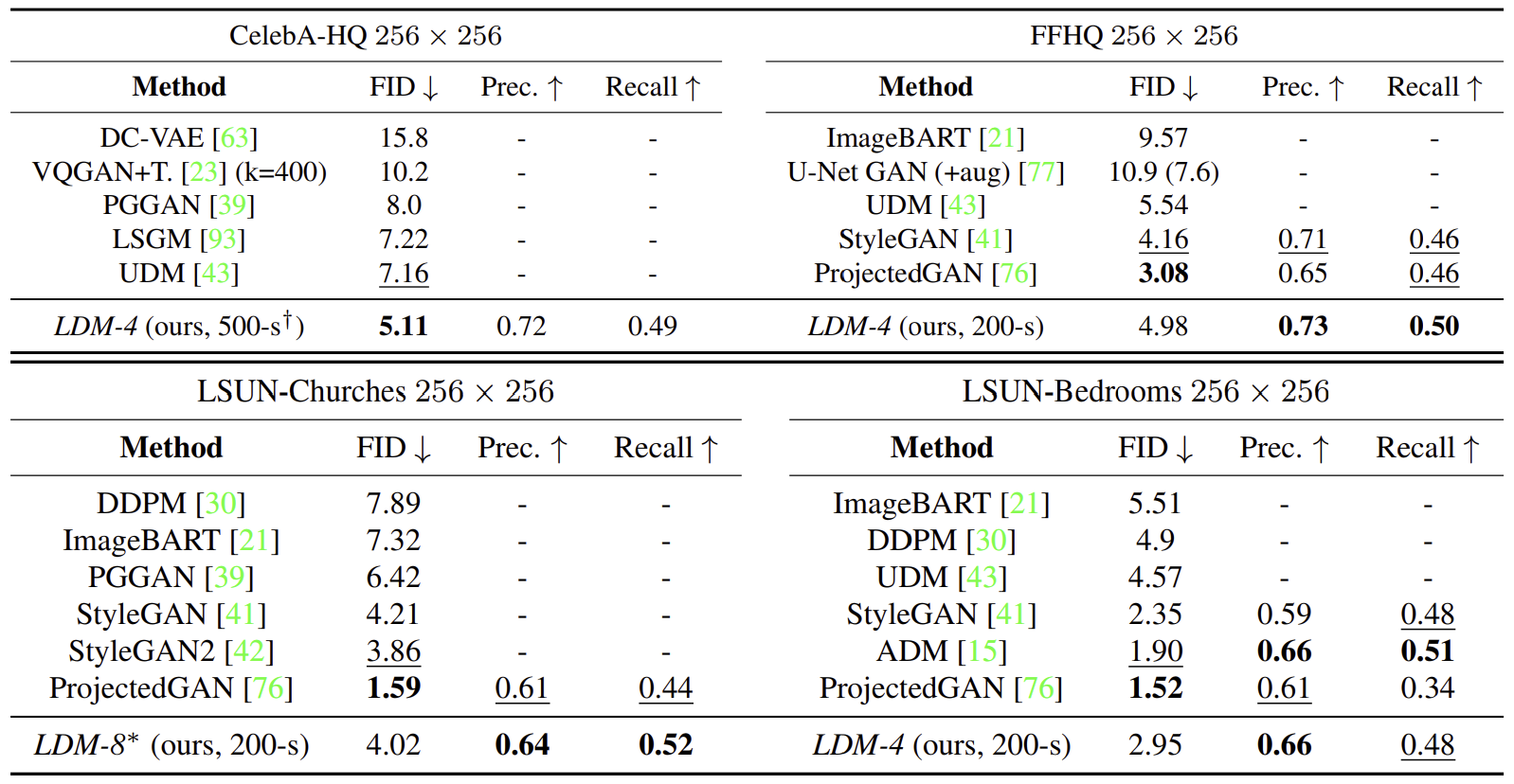
4.2. Image Generation with Latent Diffusion
4.3. Condition Latent Diffusion
4.3.1. Transformer Encoders for LDMs
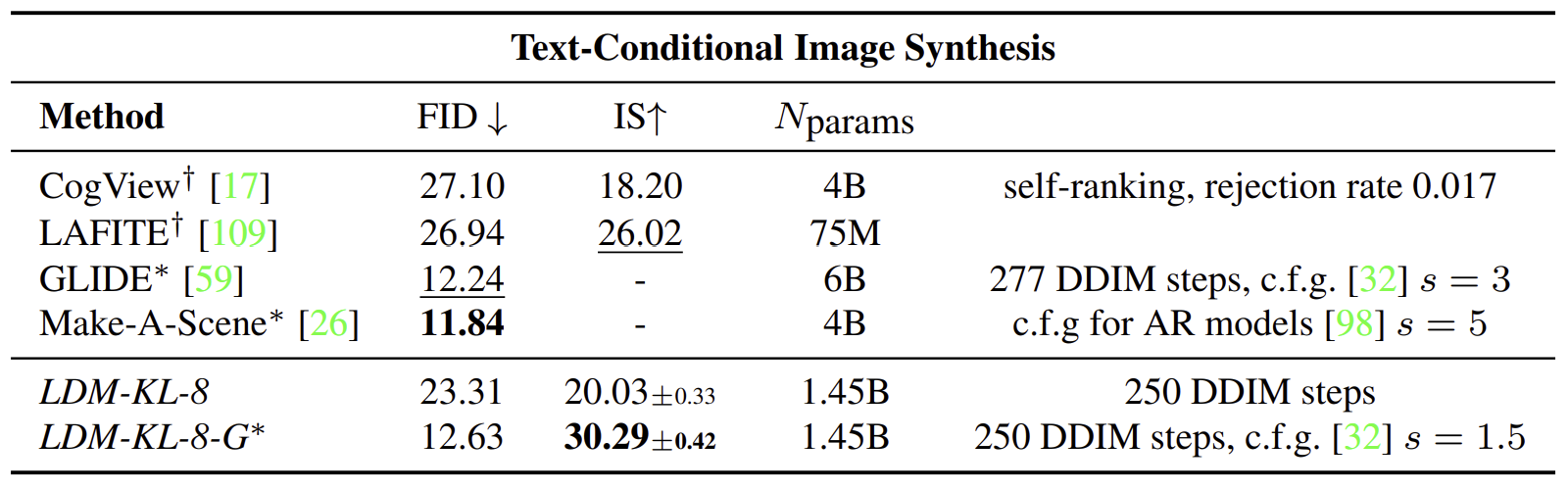
MS-COCO validation set에 대해서 T2I 성능을 검증했습니다. LDM는 다른 모델들보다 뛰어난 성능을 보였는데, 특히 classifier-free guidance를 적용했을 때 더 뛰어난 성능을 보인다고 합니다.

4.3.2. Convolutional Sampling Beyond 256^2
$\epsilon_{\theta}$에 spatially aligned condition을 넣어주면 image-to-image 작업도 가능합니다. 이는 맥락 형성(semantic synthesis), 초해상화(super resolution, 4.4절), 이미지 복구(inpainting, 4.5절)로도 확장될 수 있습니다. 맥락형성의 경우 semantic map을 이미지와 함께 넣어주는데, 합성곱 방식을 사용하면 $256^2$ 해상도 이상의 크기까지도 생성이 가능하다고 합니다. 이 특징을 사용하면 초해상화를 구현할 수 있습니다(4.4절).

4.4. Super-Resolution with Latent Diffusion
실험은 S3모델을 기반으로 합니다. OpenImages 데이터셋에서 미리 학습된 f=4의 autoencoder를 사용하며, UNet에 저해상도의 이미지를 함께 입력하게 됩니다. 여기서 $\tau_{theta}$는 아무 변환도 하지 않는 항등 함수로 둡니다.



4.5. Inpainting with Latent Diffusion
실험은 LaMa모델을 기반으로 합니다. 여기서는 추가적으로 크기를 키운 LDM big 모델도 만들어 비교합니다. LDM big은 UNet에 attention + BigGAN의 residual blocks을 사용했으며, 매개변수 수가 215M에서 387M로 증가했습니다. 단, 이 경우 512 * 512 해상도에서 성능이 떨어져 1/2 epoch 만큼의 추가 fine-tuning이 있었습니다.


5. Limitations & Societal Imapct
5.1. Limitations
LDMs는 pixel-based모델에 비해 계산 성능이 더 뛰어나지만, 여전히 GAN 모델들에 비해서는 sampling 속도가 빠르지 않습니다. 또한 fine-grained accuracy 작업에서 병목이 존재하여, 정밀한 결과값이 필요한 경우에는 적절하지 않다는 문제도 있습니다.
5.2. Societal Impact
생성형 모델은 양날의 검과 같습니다. 생성형 모델은 창의적인 작업을 가능하게 하며, 본 연구의 모델 처럼 훈련 및 추론 비용을 줄이는 접근법은 기술의 민주화에 기여할 수 있습니다. 하지만 이는 조작된 이미지나 허위 정보, 스팸의 생산과 유포를 쉽게 할 수 있다는 뜻이기도 합니다.
또한 모델이 훈련 데이터의 일부를 드러낼 수 있는 문제가 존재합니다. 민감하거나 개인적인 정보가 포함된 데이터의 경우, 동의 없이 수집된 데이터가 유출의 우려가 있으나 이에 대해서는 정확하게 연구되지 않았습니다.
마지막으로 데이터의 편향을 그대로 반영할 수 있다는 것입니다. DMs은 GANs보다 데이터 분포를 잘 커버하는 편이지만, 본 연구에서 사용한 두 단계 모델(Adversarial + Likelihood 기반) 이 데이터를 얼마나 왜곡하는 지는 추가적인 연구가 필요합니다.
6. Conclusion
본 연구에서는 간단하지만 효과적으로 학습과 추론 시간을 단축시킨 Latent Diffusion Model을 소개하였습니다. 이는 cross-attention과 degrading을 이용하여 SotA 모델들과 비교하여 다양한 이미지 생성 작업에서의 성능이 뛰어나다는 것을 보여주었습니다.