NIPS 2012에 발표된 논문입니다.
NIPS | https://papers.nips.cc/paper_files/paper/2012/hash/6aca97005c68f1206823815f66102863-Abstract.html
Abstract
비지도 학습과 딥러닝에 대한 연구는 모델의 크기가 클수록 그 성능이 비약적으로 향상된다는 것을 밝혔습니다. 이 논문에서는 이러한 대규모 모델을 학습하는것에 대한 문제점의 해결방안에 대해 논합니다. 그리고 이를 바탕으로 수천 개의 장치를 이용해 computing cluster를 구축할 수 있는 SW 프레임워크인 DistBelif를 구현했습니다. 이 프레임 워크에는 두 가지 알고리즘이 구현되었습니다. Downpour SGD는 비동기적 SGD를 수행하여 다수의 장치들을 이용할 수 있습니다. Sandblaster는 다양한 배치 최적화를 지원합니다. 이 둘 모두 모델의 규모와 속도를 향상시킬 수 있음을 보였습니다. 이 논문은 주로 대규모 모델에 초점을 두었지만, 다른 gradient 기반 알고리즘에도 얼마든지 적용할 수 있습니다.
1. Introduction
최근 연구에서 딥러닝 모델의 크기가 classification 문제의 정확도에 영향을 준다는 것이 밝혀지면서, 대규모 학습에 대한 관심이 증가하게 되었습니다. 이에 따라 GPU 학습도 주목받고 있으나, 모델이 GPU 메모리에 맞지 않는 경우 오히려 속도가 저하된다는 단점이 존재합니다. CPU-GPU 전달의 병목을 줄이기 위해 데이터나 매개변수를 줄이는 방법도 있지만, 결국 대규모의 모델에서는 효과가 없었습니다.
이 논문은 그 대안으로 대규모 클러스터를 만들어 학습하는 방법을 제시합니다. DistBelif는 장치 사이의 model parallelism과 함수를 계산할 때의 data parallelism을 수행할 수 있습니다. 이를 위해 두 가지 기법이 구현되었습니다. Downpour SGD는 비동기적 SGD를 수행하며, Sandblaster L-BFGS는 데이터와 모델을 병렬 계산하는 L-BFGS의 분산 버전이라고 할 수 있습니다. 두 가지 기법 모두 nonconvex 최적화에서 다른 SGD 기법들보다 더 좋은 성능을 보여주었습니다.
이 논문에서 제시한 모델은 대규모 모델을 학습시킬 수 있으며, 보통 수준의 모델도 굉장히 빠른 속도로 학습시킬 수 있습니다. 이는 각각 ImageNet 학습과 speech 모델 학습을 통해 증명했습니다.
2. Previous work
Paralleization and distribution
- Linear & Convex model
- Delayed gradient update for convex problem
- Sparse gradients asynchronously
=> 논문의 목표 : convex problem & sparse problem 없이 asynchronous macines cluster를 사용하는 것
Scaling up deep learning
- Farm of GPU
- Modifying networks
- One dominated layer
=> 논문의 목표 : 적합한 분산 최적화 기법을 통해 병렬계산
3. Model paralleism
대규모 딥러닝 모델의 빠른 학습을 위해 이 논문은 DistBelif라는 SW 프레임워크를 개발했습니다. DistBelif는 신경망과 layered graphical model에서 분산계산을 적용할 수 있도록 도와줍니다. 사용자는 각 layer의 모드마다 어떤 계산을 할 것인지, 그리고 계산을 수행할 때 어떤 메세지를 전달할 것인지를 지정합니다. 대규모 모델에서는 모델을 몇 개의 구간으로 나눠 가 장치에 할당되도록 해야 합니다(Figure 1).

이 원리는 모델의 계산 수준이나 연결된 구조에 따라 그 성능이 달라집니다. 매개변수가 많거나 복잡한 계산을 해야 하는 모델은 CPU와 메모리가 더 많이 필요하기 때문에 높은 성능을 보일 수 있습니다. 그리고 지역적으로 연결되어 있는 구조가 fully connected 구조보다 분할하기 더 쉬워 높은 성능을 보입니다. 다른 장치들 간의 처리 시간도 speedup에 영향을 주는데, 느린 장치가 있으면 병목현상이 발생할 수 있기 때문입니다. 이 논문에서 제시한 구조는 모든 장치가 평균적인 CPU utilization을 발휘할 수 있도록 할 수 있습니다.
4. Distributed optimization algorithms
대규모 모델을 적절한 시간에 학습시키기 위해서는 하나의 모델 instance 뿐 아니라 여러 개의 모델 instance들 사이의 병렬 계산도 고려해야 합니다.
이를 위해 두 가지 알고리즘을 비교하게 되었습니다. Online 기법의 Downpour SGD와 batch 기법의 Sandblaster L-BFGS인데, 두 가지 모두 모델의 복제본에 매개변수를 분배할 수 있도록 합니다. 중요한 점은 이 기법들이 서로 다른 복제본들이 처리 속도 차이가날 수 있도록 하거나 대규모 장애에도 대처할 수 있도록 설계되었다는 것입니다.
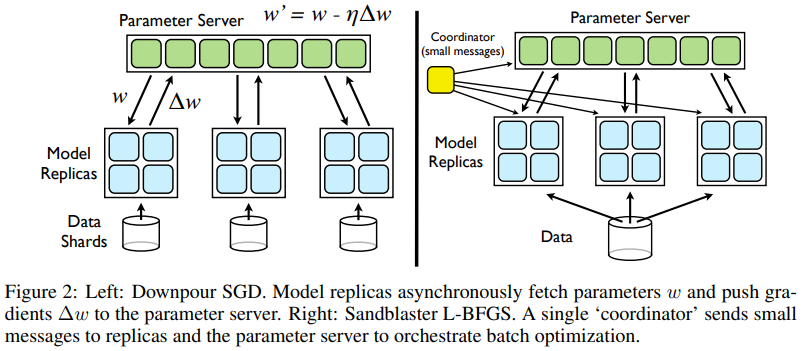
4.1. Downpour SGD
기존의 SGD는 순차적 처리로 인해 많은 양의 데이터셋을 처리하기 비효율적이었습니다. 이 논문은 큰 데이터셋에서의 처리를 위해 downpour SGD를 도입했습니다. 이는 여러 복제본을 사용하는 비동기적 SGD로, 데이터셋을 각 부분으로 나누어 각각의 복제본 모델에서 실행하게 됩니다. 이 모델들은 매개변수 상태를기록하는 중앙 매개변수 서버를 통해 갱신사항을 공유하게 됩니다. 매개변수 서버는 여러 장치들이 매개변수 값을 분담하여 기록하는 형태로 구성되어 있습니다(Figure 2). 매개변수 서버를 포함한 각 복제본 모델들이 다른 모델들과 별개로 작동하기 때문에, 이 방식은 비동기적이라고 할 수 있습니다.
각 장치에 할당된 모델 복제본들은 mini-batch를 계산하기 전에 매개변수 서버에 매개변수의 갱신이 가능한지 확인합니다. 매개변수의 갱신값을 받으면, 복제본들은 gradient를 계산하여 그 결과를 매개변수 서버에 갱신합니다. 여기서 특정 step에서만 매개변수를 요청($n_{fetch}$)하거나 gradient를 갱신($n_{push}$)하도록 한다면 장치간 통신으로 인한 overhead를 줄일 수 있습니다. 계산과 비교의 편의를 위해, 이 논문에서는 $n_{fetch} = n_{push} = 1$로 설정했습니다.
Downpour SGD는 비동기적입니다. 동기적 SGD라면 한 장치에서 장애가 일어났을 때 다른 장치가 작업을 마저 맡아 수행할 수 있지만, 비동기적 SGD에서는 좀 더 복잡한 방법이 필요합니다. 복제본들이 매개변수를 요청하거나 gradient를 갱신하는 것을 고려하면 매개변수의 일관성을 떨어질 수 밖에 없기 때문입니다.
이 논문은 이에 대한 해결책으로 nonconvex problem보다 비교적 간단한 Adagrad adaptive learing rate procedure라는 방법을 찾아내었습니다. Adagrad는 learning rate를 고정하지 않고 매개변수마다 서로 다른 값을 사용합니다.
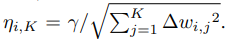
$\eta_{i, K}$ : iteration K에서 i번째 매개변수에 대한 learning rate
$\Delta_{w_i, K}$ : iteration K에서 w의 매개변수
$\gamma$ : 상수. Adagrad를 적용하지 않을 때 최적 learning rate보다 높게 설정
Adagrad는 동시에 수행할 수 있는 복제본 수를 늘리고, 안정성 문제를 해결할 수 있습니다.
4.2. Sandblaster L-BFGS
Sandblaster의 핵심 아이디어는 매개변수의 분산 저장 및 관리를 하는 coordinator process에 있습니다(Figure 2). Coordinator는 매개변수에 직접 접근하지 않고 간단한 연산(dot product, scaling, addition, multiplication)과정에서 매개변수를 요청합니다. 이 연산들은 독립적인 샤드에서 수행되기 때문에, 그 결과도 같은 샤드 내에 저장됩니다. 따라서 중앙 서버에 모든 매개변수와 gradient 값을 넘길 필요가 없기 때문에, overhead를 줄일 수 있게 됩니다.
이 논문에서는 장치의 병목현상으로 인한 대규모 클러스터에서의 장애를 해결하기 위해 load balancing이라는 기법을 활용했습니다. 이 방법은 coordinator가 N개 장치에 전체 배치의 1/N보다 더 작은 작업량을 할당한 후, 여유가 생기는 장치마다 새로운 작업들을 할당해줍니다. 이후 마지막 작업이 남으면, 해당 부분을 복사하여 다른 장치에도 할당시켜 먼저 작업이 끝나는 장치의 결과값을 사용하게 됩니다. 따라서 빠른 장치는 느린 장치보다 더 많을 일을 수행할 수 있게 됩니다.
사용빈도가 높고 매개변수 동기화 범위가 넓은 downpour SGD와는 달리, Sandvlaster는 특정 구간에서만 매개변수를 불러오고 gradient를 갱신하게 됩니다.
5. Experiments
두 알고리즘에 대한 성능 평가를 이미지 인식과 발화 인식 두 가지 상황에 대해 수행했습니다.
Model parallelism benchmarks
DistBelif의 병렬계산을 평가하기 위한 것으로, 사용하는 장치의 수에 따라 미니배치 하나를 처리하는데 걸리는 평균 시간을 측정했습니다. Figure 3.은 사용 장치 수에 따른 계산 결과를 speedup을 통해 나타낸 것입니다. Speech task의 경우 8개 장치 이상으로는 network overhead로 인해 학습이 느려지는 것을 볼 수 있습니다. 이에 반해 local connectiviy가 강한 image task의 경우 장치가 많아질 수록 speedup도 증가함을 볼 수 있습니다.

Optimization method comparisons
분산 최적화를 평가하기 위해서는 speech 모델을 다양한 설정에서 실행했습니다.
Baseline : 기존 SGD의 DistBelif / CUDA GPU 환경에서의 DistBelif
Comparison : fiex lr downpour / Adagrad lr downpour / Sandblaster L-BFGS

가장 빠른 것은 200개의 모델 복제본을 사용한 Downpour SGD + Adagrad(빨간색)입니다. 만약 충분한 CPU 리소스에 액세스할 경우, Sandblaster L-BFGS 와 Downpou SGD + Adagrad는 고성능 GPU보다 훨씬 빠르게 모델을 학습시킬 수 있음을 보여주었습니다.
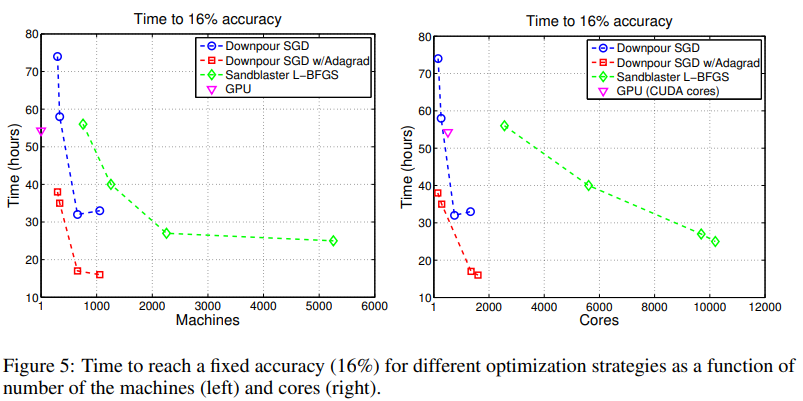
사용 장치의 수와 성능 사이의 trade-off 관계를 파악해볼 수도 있습니다. 테스트 정확도(16%)를 임의로 고정 한 후, 각 기법이 그 정확도에 도달하는 데 걸린 시간을 장치와 사용된 CPU 코어의 함수로 측정합니다.
그림5.에서 원점에 가까운 지점일수록 적은 시간 동안 적은 장치를 사용하기 때문에 좋은 기법입니다. 따라서 Downpou SGD + Adagrad가 제일 좋은 성능을 발휘한다고 볼 수 있습니다. Sandblaster L-BFGS의 경우는 만약 충분히 많은 장치가 주어진다면 굉장히 빠른 처리시간을 보여줄 것입니다.
Application to ImageNet
이 알고리즘을 더 큰 모델로 확장할 수 있음을 확인하기 위해, Downpour SGD를 사용하여 ImageNet의 이미지 분류 작업을 학습시켰습니다. 이 네트워크는 21,000 개의 카테고리 ImageNet 분류 작업에서 알려진 최고 성능보다 60% 이상 상대적으로 향상된 교차 확인 분류 정확도를 달성했습니다.
6. Conclusions
이 논문에서는 딥러닝 모델의 병렬 분산 학습을 위한 프레임워크인 DistBelief를 소개했습니다. DistBelif는 효과적인 분산 최적화 알고리즘인 Downpour SGD와 Sanblaster L-BFGS를 구현했습니다. Downpour SGD는 nonconvex 딥러닝 모델을 잘 학습시키는 것을 보여주었고, Sandblaster는 네트워크 대역폭을 더 효율적으로 사용하여 단일 모델 학습에서 더 많은 코어를 사용할 수 있게 합니다. 결론적으로 2000개 이하의 CPU 코어를 사용하는 경우, Downpour SGD와 Adagrad를 사용하는 방법이 최고의 성능을 보여주었습니다.
Adagrad와 비동기적 SGD는 원래 함께 사용되지 않았으며, 두 기법 모두 nonconvex problem에도 사용되지 않았습니다. 때문에 이 두 방법이 고도로 비선형적인 딥러닝 모델에서 잘 작동한다는 것은 상당히 놀라운 점입니다. 이에 대해 Adagrad가 비동기 방식에서 불안정한 매개 변수를 안정화시키고, learning rate를 신경망 layer의 조건에 맞게 조절하는 것으로 추측하고 있습니다.
또한 이 논문에서 제시한 방법이 장치 클러스터를 이용하여 GPU보다도 더 빨리 학습시킬 수 있음을 보여주었습니다. 더 큰 모델을 학습시킬 수 있음을 보여주기 위해 10억 개 이상의 매개 변수를 가진 모델을 훈련하여 ImageNet 객체 인식 도전에서 최신 기술 성능을 달성하기도 했습니다.