

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- CSS
- vscode
- GAN
- python
- UI
- js
- Linux
- C++
- postgresql
- sqlite
- review
- SOLID
- ps
- PyTorch
- Express
- html
- ML
- nodejs
- mongo
- PRISMA
- frontend
- API
- DM
- react
- Git
- ts
- CV
- DB
- Three
- figma
- Today
- Total
아카이브
[Pytorch] 적대적 생성 모델(GAN)의 hyperparameter값에 따른 변화 본문
인공 신경망을 만들 때는 많은 종류의 hyperparameter가 사용됩니다.
이것들이 모델의 방향성을 결정하기 때문에, 모델의 성능에 직접적으로 영향을 주는 중요한 요소입니다.
따라서 앞서 구현한 GAN을 기반으로 hyperparameter의 값을 바꿔가며 그에 따른 변화를 확인하고자 합니다.
1. Amount of layers
원본에서는 L1, L2, L3 세 개의 linear layer를 사용했습니다. 여기서 linear layer를 하나 더 추가해보았습니다.


# hyperparamter
max_epoch = 200
batch_size = 100
lr = 0.0002
img_size = 784
noise_size = 100
hidden_size1 = 256
hidden_size2 = 512
hidden_size3 = 1024 ## <changed> ##
loss = nn.BCELoss()
# nn.Module : Base class for all neural network modules.
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(noise_size, hidden_size1)
self.linear2 = nn.Linear(hidden_size1, hidden_size2)
self.linear3 = nn.Linear(hidden_size2, hidden_size3)) ## <changed> ##
self.linear4 = nn.Linear(hidden_size3, img_size) ## <changed> ##
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
def forward(self, x):
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.relu(self.linear3(x))
x = self.tanh(self.linear4(x)) ## <changed> ##
return x
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(img_size, hidden_size3) ## <changed> ##
self.linear2 = nn.Linear(hidden_size3, hidden_size2) ## <changed> ##
self.linear3 = nn.Linear(hidden_size2, hidden_size1))
self.linear4 = nn.Linear(hidden_size1, 1)
self.relu = nn.LeakyReLU(0.2)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.relu(self.linear3(x))
x = self.sigmoid(self.linear4(x)) ## <changed> ##
return x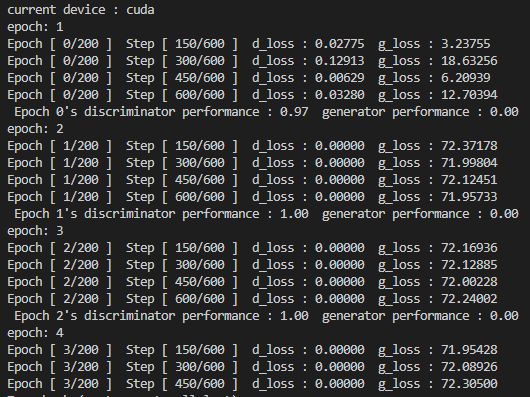

실행결과 두 번째 epoch에서부터 discriminator의 loss가 0으로 나오면서(discriminator가 항상 참을 출력)
학습이 불가능해졌습니다. 200 epoch 째에 생성된 이미지는 다음과 같이 유의미한 결과를 내지 못했습니다.
Time performance는 1698s 입니다.
2. Learning rate
원본에서는 Adam의 learning rate를 0.0002로 설정했습니다. 이를 0.0001 단위로 증감시켜 실행해보았습니다.


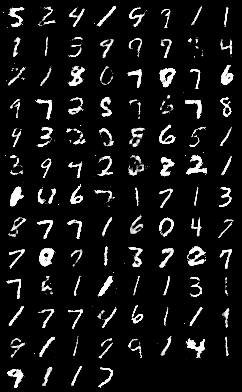

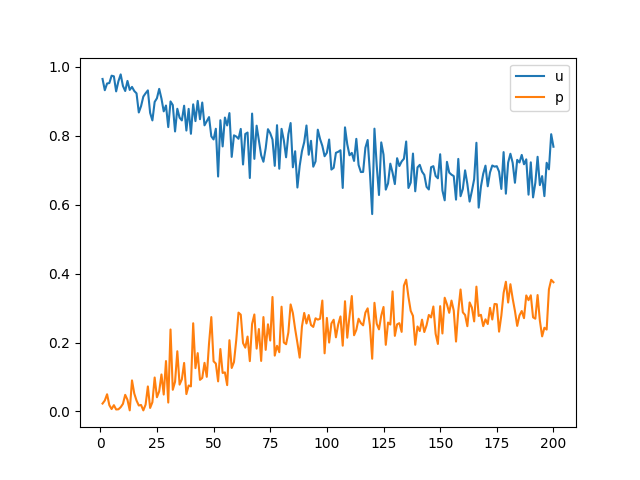
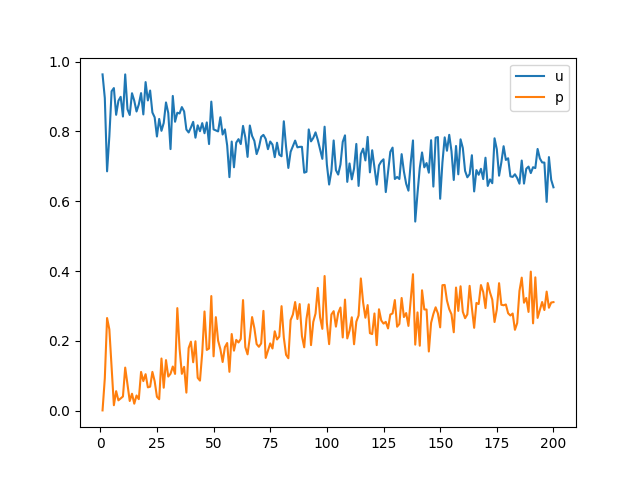
200 epoch 째 이미지를 비교했을 때 learning rate 증감에 따른 차이는 크게 차이가 나지 않습니다.
그러나 epoch에 따른 performance_D와 performance_G의 변화를 비교했을 때 learning rate가 증가함에 따라 수렴하는 위치가 중앙에 가까워지는 것을 확인할 수 있습니다.
Time performance는 0.0001일 때 1548s, 0.0002일 때 1580s, 0.0003일 때 1581s입니다.
시간 차이가 크게 나지 않아 변화 폭을 작게 준 것인지, 혹은 0.0002가 극소점이 아닌 것인지 확인할 필요가 있습니다.
3. Batch size
원본에서는 60000개의 데이터를 크기 100의 batch로 나누어 1 epoch 당 600회 계산을 했습니다.
해당 batch 크기를 50, 200으로 바꾸어 실행해보았습니다.
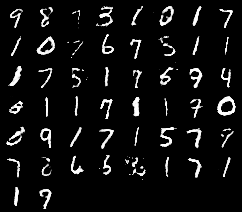

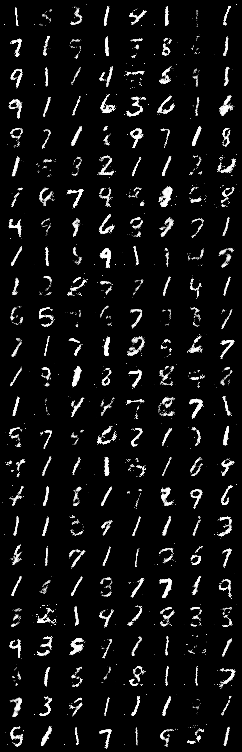
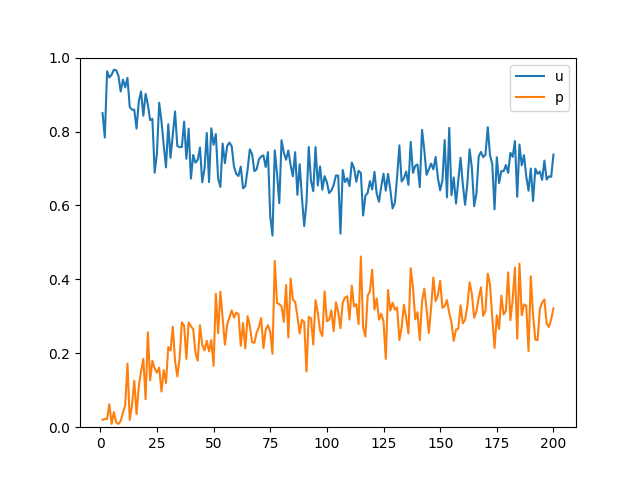

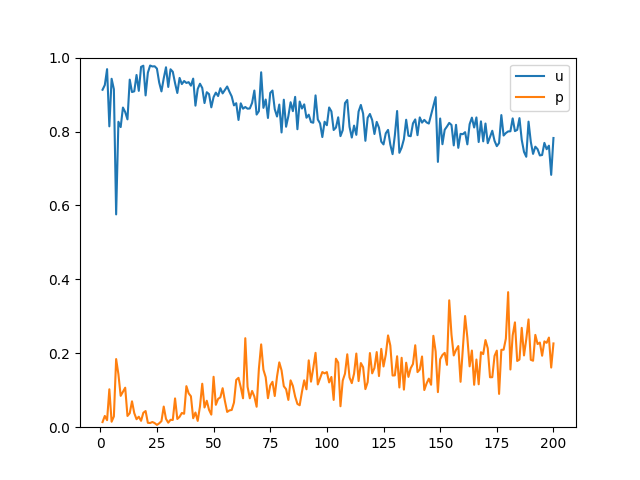
200 epoch 째 이미지를 비교했을 때 batch size가 증가할 수록 깨진 이미지의 빈도가 높아지는 것을 확인할 수 있습니다.
또한 loss 변화를 관찰했을 때 또한 batch size가 증가하면 수렴값이 중앙에서 멀어지게 됩니다.
이는 batch의 크기가 작을 수록 학습 횟수가 늘어나 피드백이 많이 발생하기 때문입니다.
단, 과도한 빈도의 학습은 해당 데이터셋에서만 적합하게 되는 과적합(overfitting)을 유도할 수 있습니다.
4. Noise vector
원본에서는 100 크기의 noise vector를 기반으로 이미지를 생성했습니다.
해당 noise vector 크기를 50, 200으로 바꾸어 실행해보았습니다.
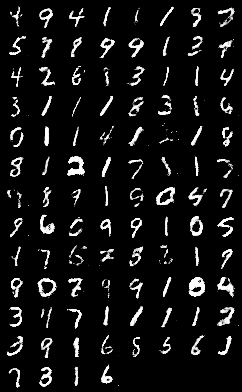


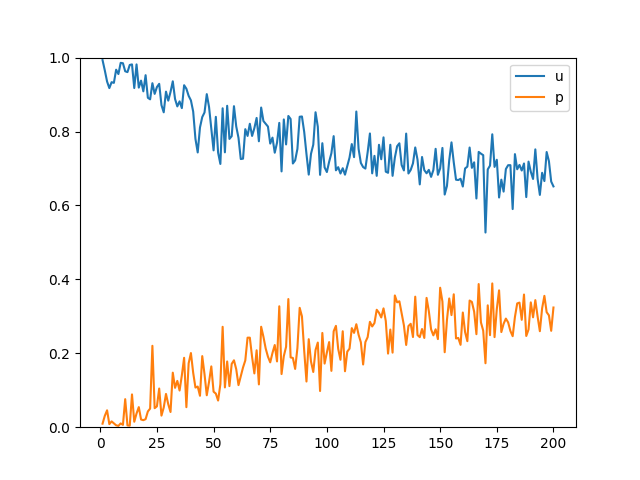

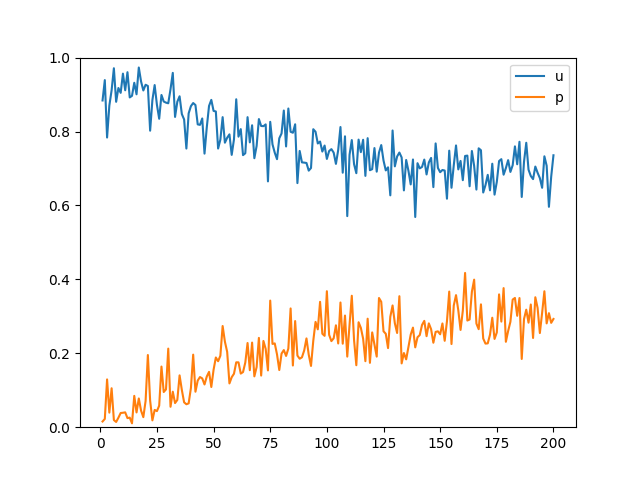
200 epoch 째 이미지와 loss 변화를 비교했을 때 noise vector 크기 증감에 따른 차이는 크게 차이가 나지 않습니다.
'Pytorch' 카테고리의 다른 글
| [Pytorch] 조건 적대적 생성 모델(CGAN) 구현하기 - MNIST를 기반으로 (0) | 2023.02.16 |
|---|---|
| [Pytorch] 적대적 생성 모델(GAN) 구현하기 - MINST를 기반으로 (0) | 2023.02.11 |
| [Pytorch] Pytorch 함수 정리 (0) | 2023.02.06 |
| [Pytorch] pip로 Pytorch 설치하기 (0) | 2023.01.24 |


