StyleGAN은 style transfer를 기반으로 인물의 구체적인 특징(style)을 구분하여 부분적으로 합성할 수 있게 해줍니다. 따라서 StyleGAN의 구조에 있어서 얼마나 style을 잘 잡아내는지, 그 style이 다른 style의 변화에 영향을 주지 않고 독립적인지를 따져보아야 합니다.
1. 개요
구조 설명에 앞서 몇 가지 용어를 알아야 합니다.
1.1. Entanglement / disentanglement
앞서 말했듯이 styleGAN에서 중요한 점은 어떤 style이 다른 style에게 영향을 미쳐서는 안된다는 것입니다.
만약 각각의 style들이 서로에게 영향을 주는 상태라면 이를 engtangled라고 부릅니다.
반대로 각각의 style들이 독립적으로 존재한다면 disentangled라고 할 수 있습니다.
따라서 styleGAN을 설계할 때 우리의 목표는 style들을 최대한 disentangled 하게 만들 수 있도록 설계하는 것입니다.
1.2. Latent space / Latent code / Latent vector
신경망은 입력 데이터를 받을 때 신경망 모델에 적합한 형태의 수치로 변환하여 입력을 받게 됩니다.
예를 들어 이미지의 경우 RGB 세 개의 채널과 가로 세로 두 개의 축이 있는 tensor로 변환하여 입력받게 됩니다.
이와 같이 데이터의 특징을 나타내는 vector / code 를 Latent vector / Latent code 라고 부릅니다.
그리고 이 Latent vector가 이루는 공간을 Latent space라고 부릅니다.
2. 구조
StyleGAN은 크게 mapping network와 synthesis network두 가지 부분으로 나누어져 있습니다.
하여 기존의 GAN과는 다르게 입력값(z)이 generator(여기서는 synthesis network)에 바로 들어가는 것이 아닌,
mapping network를 거치고 generator의 중간부터 들어가게 됩니다.
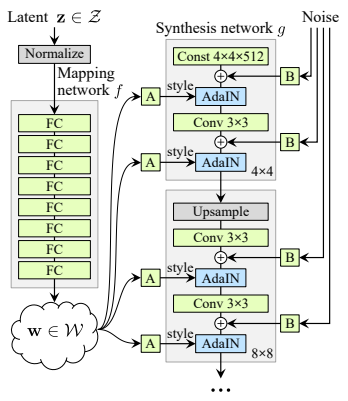
2.1. Mapping network
입력값인 latent vector z를 학습한 데이터들과 비슷한 확률분포로 만들기 위해서 비선형 변환을 시킵니다.
여기서 비선형 변환을 f라고 할 때, f는 latent space Z 에서 latent space W로 가는 함수입니다.
결과적으로 W의 각 원소들은 서로 각각 특징을 나타내는 latent code가 되며, disentangled 하게 변형됩니다.
(Z와 W의 크기는 같습니다)
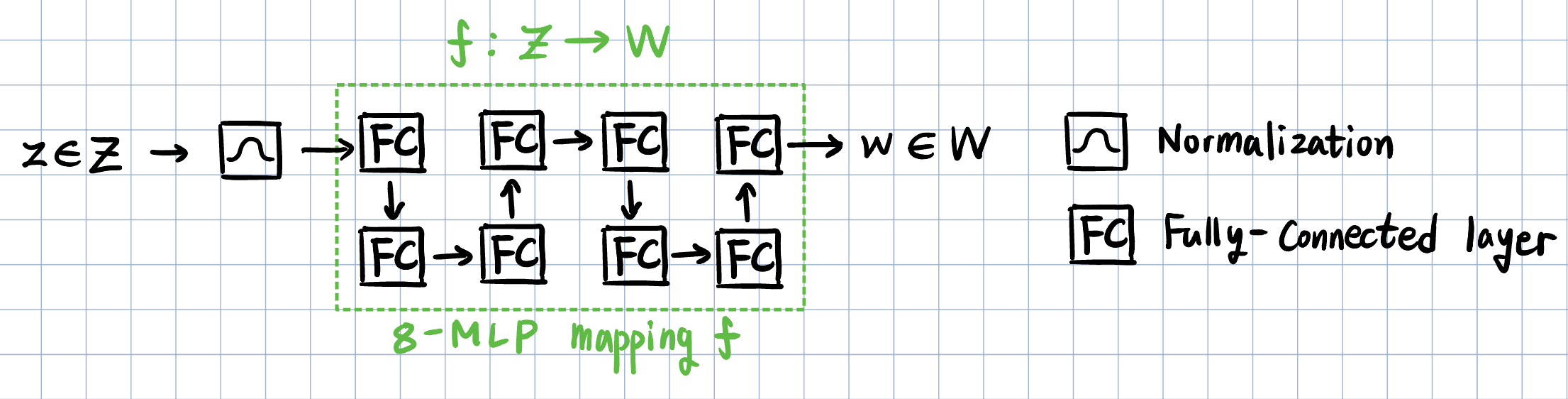
2.2. Synthesis network
Synthesis network g에서는 본격적인 이미지 생성이 시작됩니다.
입력값은 latent vector z 대신 상수를 집어넣습니다. 앞서 mapping network를 통해 구한 w는 g의 중간 부분부터 들어가고, 이 w의 원소들이 각각의 style을 나타내게 됩니다.
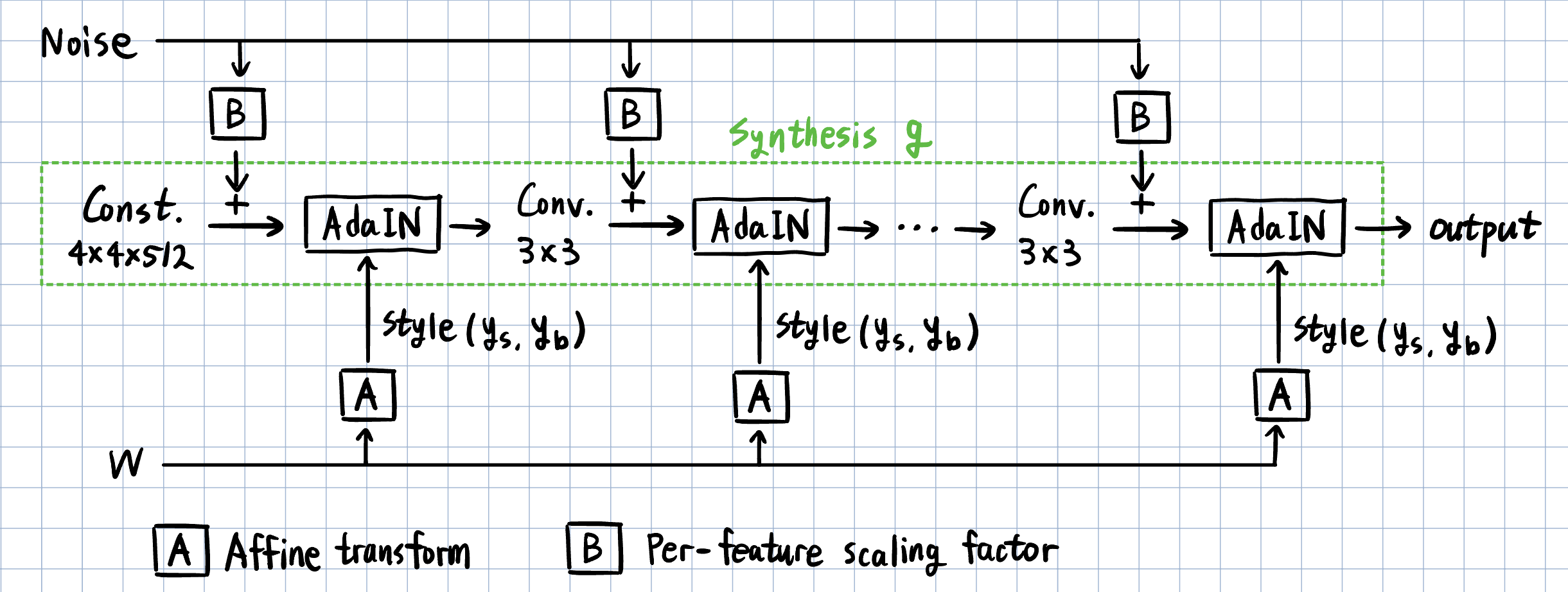
2.2.1. Latent vector w
w의 각 원소들은 아핀변환(Affine transformation)을 거치며 (ys, yb) 두 개의 원소를 가지는 style vector로 변환됩니다.
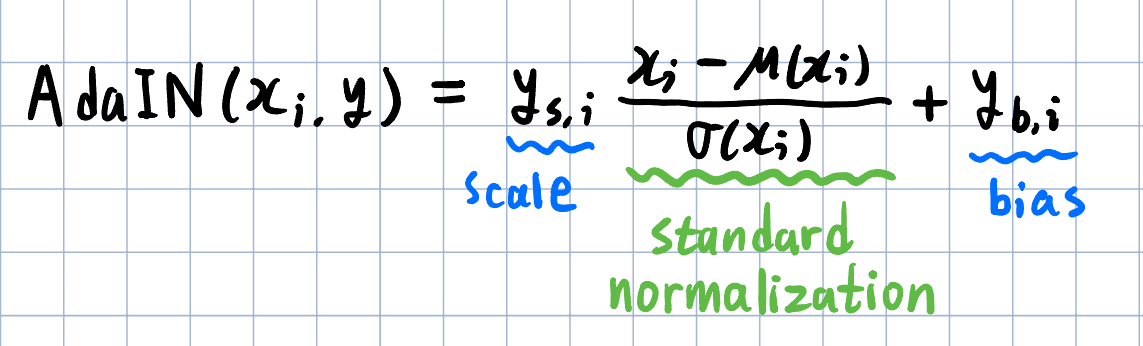
ys는 크기(scaling factor), yb는 편향(biased factor)을 의미하며, g 내부의 AdaIN 연산의 매개변수로 사용됩니다.
AdaIN 연산은 다음과 같이 정의됩니다.
이를 통해 latent vector w의 각 원소는 g의 각 단계에 삽입되어 초기 상수 Const.의 값을 변형하게 됩니다.
이 때 w의 각 원소는 다음 Convolution Layer에만 영향을 미치니 각각의 style이 독립적으로 작용한다고 볼 수 있습니다.
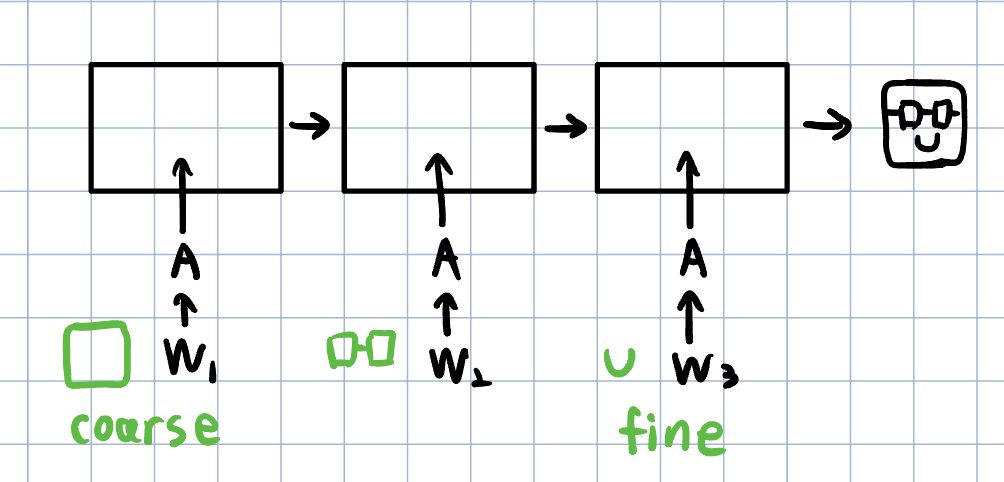
w의 원소들은 언제 삽입되느냐에 따라 적용되는 범위가 달라집니다.
초기에 들어가는 style 일수록 더 많은 layer들을 통과하므로 그 영향이 이미지 전체에 걸쳐 적용됩니다. 이는 거시적인 style로 나타나고, coarse style이라고 합니다.
끝부분에 들어가는 style은 연산량이 적어 이미지에 조금밖에 적용되지 못합니다. 이는 국지적인 style로 나타나고, fine style이라고 합니다.
2.2.2. Noise
추가적으로 이미지의 세부적인 요소(머리카락, 주근깨 등)를 구현하기 위해서 각 픽셀마다 noise를 추가합니다. Noise 또한 g 내부의 중간 계층에 더해지는데, 이 때는 아핀 변환이 아닌 per-feature scaling factor로 연산을 합니다.
3. 성질
3.1. Style mixing
Latent vector w는 이미지 각각의 style들을 요소로 가지고, 이는 모두 독립적입니다.
이 말은 곧 서로 다른 latent vector w1, w2의 요소들을 섞으면 두 이미지의 style이 섞인 새로운 이미지를 만들 수 있다는 뜻입니다.
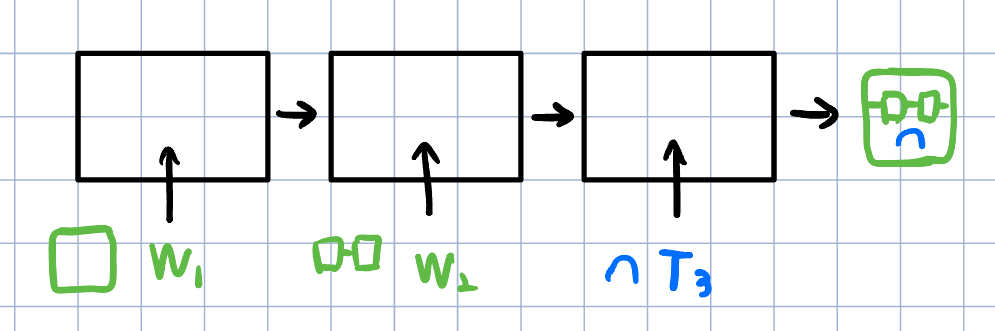
3.2. Stochastic variation
앞서 언급했듯 머리카락, 주근깨, 수염과 같이 무작위성이 짙은 특징들은 style로는 잘 살리기가 어렵습니다.
따라서 이러한 확률적 변형(stochastic variation)이 존재하는 부분은 noise를 삽입함으로서 해결할 수 있습니다.
Style과 마찬가지로 noise도 삽입되는 위치에 따라 coarse와 fine으로 구분되는데,
fine noise가 많아질수록 세부사항이 더 자세해지고 coarse noise가 많아질수록 세부사항이 단순화됩니다.
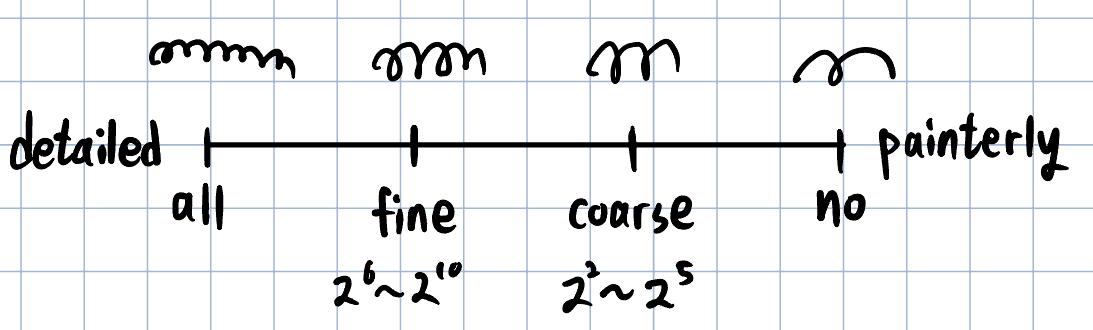
4. 최적화
StyleGAN의 성능은 크게 두 가지 기준으로 평가할 수 있습니다.
첫 번째는 생성과정이 얼마나 disentangled 한지를 평가하는 perceptual path length이고,
두 번째는 입력값으로부터 latent vector를 얼마나 잘 생성하는지를 평가하는 separability입니다.
4.1. perceptual path length
한 이미지 A가 다른 이미지 B로 변할 때 얼마나 지각적으로 자연스럽게(=직관적이게) 변하는지를 나타내는 길이입니다.
경로가 짧을 수록 이미지는 자연스럽게 변하고, 경로가 길거나 돌아갈 수록 중간과정으로 전혀 관계 없는 이미지가 나올 수 있습니다.

4.2. Linear separability
Latent space가 충분히 disentangled 하다면, 입력값에 대해서 latent vector를 잘 찾아낼 수 있어야 합니다. 이런 정도를 linear separability라고 합니다. 이는 SVM으로 입력값을 분류한 데이터를 모델에서 사용한 classifier로 입력값을 분류한 데이터와 비교하여 구할 수 있습니다.
'ML' 카테고리의 다른 글
| [Modal] 01. App (1) | 2025.12.30 |
|---|---|
| [Modal] App, Function, Entrypoint (0) | 2025.12.29 |
| [Modal] Modal에 대하여 (0) | 2025.12.28 |
| [GAN] 조건적 적대 생성 신경망 (CGAN) (0) | 2023.02.17 |
| [GAN] 적대적 생성 신경망(GAN) (0) | 2023.02.17 |