[review] SALAD: Part-Level Latent Diffusion for 3D Shape Generation and Manipulation
KAIST 성민혁 교수님 연구실 소속 Jil Koo, Seungwoo Yoo, Minh Hieu Nguyen의 논문입니다. 2023 ICCV에 투고되었습니다. 본문과 코드는 아래 github페이지에서 확인할 수 있습니다.
SALAD
Shuffle! AutoSDF SALAD (Ours) AutoSDF SALAD (Ours) Text-Guided Part Completion Shuffle! Input Mesh Input Gaussians Output Mesh Output Gaussians Comparison of Shape Generation DPM PVD LION Voxel-GAN Neural Wavelet SPAGHETTI Diff. of $\mathbf{z}$ Diff. of $\
salad3d.github.io
Abstract
이 연구에서는 새로운 part-level implicit 3D representation 모델인 SALAD(Shape PArt-Level LAtent Diffusion Model)를 소개합니다. SALAD는 LDMs를 이용한 3D 생성 모델로, Transformer와 연속적인 프레임워크(cascaded framework)를 이용해 기존의 다른 모델보다 더 정확하고 효율적인 생성 성능을 보였다고 합니다.
1. Introduction
현재 DMs를 이용한 생성 연구는 2D 이미지 뿐 아니라 3D 모델을 대상으로도 활발히 연구되고 있습니다. 3D diffusion의 핵심 요소는 적절한 3D 데이터를 확보하는 것인데, 이를 위해 기존의 2D 생성 모델을 3D에 적용하는 것은 비효율적입니다. 차원 수가 늘어나는 만큼, 계산을 위해 필요한 자원이 급격하게 늘어나기 때문입니다. Implicit representation 기법이 3D 생성에서 효과적인 것으로 밝혀졌지만, 여전히 부분 생성/수정과 같은 guided reverse process 작업까지 적용하기는 어렵다고 합니다.
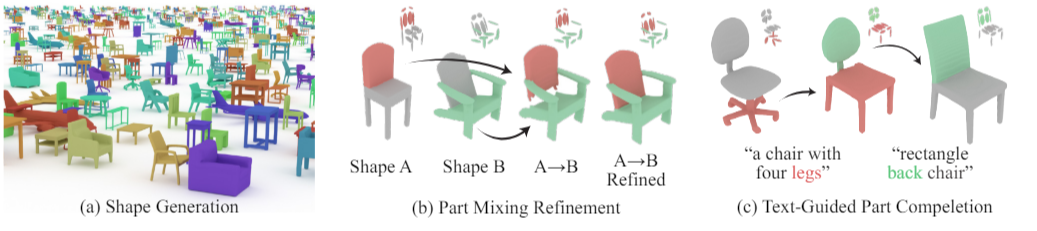
SALAD는 이러한 generation과 manipulation작업 모두 효율적으로 처리할 수 있도록 개발되었습니다. SALAD는 SPAGHETTI라는 모델을 기반으로 개발되었습니다. 이는 3D 물체를 부분으로 나누어 학습하기 때문에 부분 수정 또는 제거 작업이 수월하다는 특징이 있습니다 [그림 1]. 이 모델이 기존의 LDMs와 다른 점은 latent code가 공간이나 구조에 대한 특징을 명시적으로 표현하지 않는다는 것입니다. SALAD는 여기에 Transformer와 self-attention block을 DM 과정에 추가하고, 두 단계 과정을 거치는 two-phase cascaded 구조를 구현함으로서 보다 정확한 결과물을 낼 수 있도록 했습니다.
2. Related Work
- 3D Generative Models
- Part-Level Implicit 3D Representations : SPAGHETTI
3. Diffusion Models and Part-Level Shape Representation
3.1. Background on Diffusion Models
3.2. Part-Level Shape Representation
Neural implicit representation은 3D 생성 및 수정 모델에 널리 사용되었지만, 직관적인 수정이 어렵다는 단점이 있었습니다. 이를 해결하기위해 explicit / implicit representation을 모두 표현하는 연구들이 진행되었는데, 이를 처음 적용한 연구가 SALAD의 기반 모델이기도 한 SPAGHETTI였습니다.
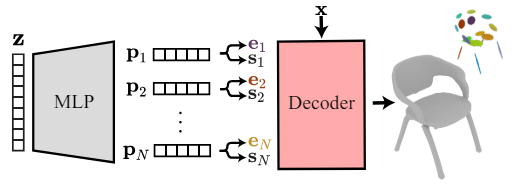
SPAGHETTI에서는 3D 입력값을 먼저 latent space z로 사영시킨 뒤, part embedding vector $\{p_i\}^N$로 변환합니다(N=단계 수). $\{p_i\}$ 는 다시 extrinsic parameter $\{e_i\}$와 intrinsic latent $\{s_i\}$로 변환됩니다.

Extrinsic parameter $e_i = \{c_i, \Sigma_i, \pi_i\}$는 각 부위의 전체적인 모양을 표현하는 Gaussian 분포를 나타냅니다($c$ : 평균, $\Sigma$ : 공분산 행렬, $\pi$ : blending weight. 전체 모양에서 차지하는 가중치). Intrinsic latent $\{s_i\}$는 부위 내의 자세한 모양을 나타냅니다. 정확히는 주어진 위치 x에 대해 3D 모양 안에 속해 있는지(1) 밖에 속해 있는지(0)를 구분하는 implicit decoder D를 학습할 수 있게 합니다.
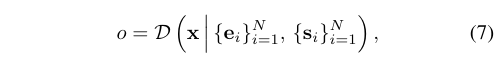
더 자세한 내용은 본 연구의 중심 내용이 아니기에, SPAGHETTI 연구를 참고하는 것이 좋습니다.
4. SALAD - Part-Level Cascaded Diffusion
SALAD는 SPAGHETTI의 아이디어에 cascaded diffusion framework를 도입하였습니다. 3.2.절에서 설명한 것과 같이 SPAGHETTI에서는 $z$, $\{p_i\}$, $\{e_i\} \& \{s_i\}$ 등 여러가지의 계층(단계)가 존재합니다. 본 연구에서는 각 단계에서 Diffusion 학습을 적용해보며 SPAGHETTI 모델의 개선점을 찾아보았습니다.
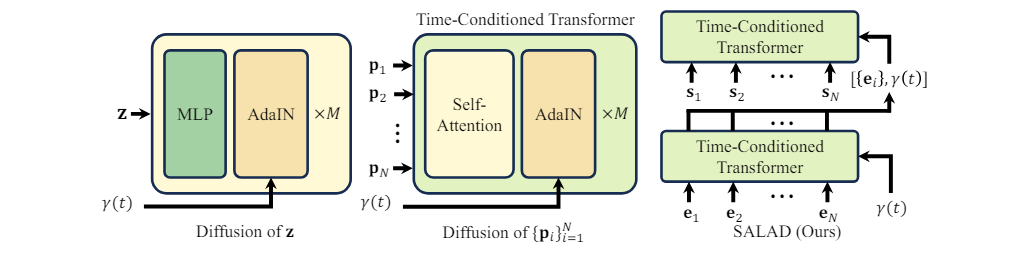
4.1. Diffusion of z
기존에 시행하던 방식입니다. 기존 DDPM의 방식처럼 ${\epsilon_{\theta}}$의 estimater를 학습하되, timestep t를 positional encoding으로 바꾼 ${\gamma(t)}$를 AdaIN 계층에서 추가하게 됩니다. 실험 결과, 단순히 latent space z를 사용할 때는 물체의 구조적 정보를 알아내기가 어려워 그 효과가 미미했다고 합니다.
AdaIN에 대한 설명은 [해당 리뷰의 2. Style-based generator] 참고.
4.2. Diffusion of $\{p_i\}$
Transformer를 적용합니다. Self-attention block이 사용되며, 4.1.과 마찬가지로 ${\gamma(t)}$를 AdaIN 계층에서 추가하게 됩니다. 이를 통해 z와 비교해서는 각 부위의 자세한 모양을 구현할 수 있었습니다. 그러나, p에서는 extrinsic & intrinsic 정보가 합쳐저 있으므로 여전히 높은 차원의 latent space에서의 diffusion은 성능이 예상만큼 좋지 않았다고 합니다.
4.3. Diffusion of $\{e_i\} \& \{s_i\}$
Cascaded diffusion을 적용합니다. 먼저 1) 낮은 차원에서 $\{e_i\}$에 대한 diffusion을 진행한 뒤, 그 결과를 바탕으로 2) 높은 차원에서 $\{s_i\}$에 대한 diffusion을 진행합니다. 두 단계 모두 4.2.와 같이 transformer를 기반으로 하며, 각각 ${\epsilon_{\theta}}$와 ${\epsilon_{\phi}}$의 estimater를 학습합니다. 이 때, 두 번째 단계에서는 ${\gamma(t)}$에 추가로 첫 번째 단계의 결과인 $\mathcal{E}(e_i)$를 함께 넣습니다. ${\epsilon_{\theta}}$와 ${\epsilon_{\phi}}$의 학습을 위한 loss function은 아래와 같습니다.
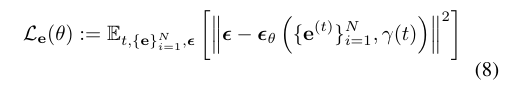
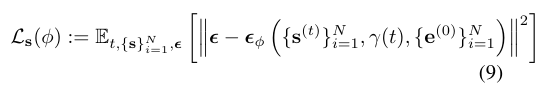
※ MLP 대신 Transformer의 self-attention block을 사용한 이유 : 해당 모델의 학습 데이터셋의 point cloud는 16개 밖에 되지 않습니다. 이 경우 point 정보 하나의 누락이 굉장히 치명적이기 때문에, point간의 상호 정보를 확인할 수 있도록 self-attention을 사용했습니다.
5. Experiment
실험에서 학습한 사물은 ShapeNet 데이터셋의 비행기(airplane)와 의자(chair) 클래스를 사용했습니다.
5.1. Shape Generation
5.1.1. Evaluation Setup
- 평가 표본 : 클래스 당 2000개 선택
- 평가 지표 : Coverage(COV), Minimum Matching Distance(MMD), 1-Nearest Neighbor Accuracy(1-NNA)
- 주요 대조군 : SPAGHETTI, NeuralWavelet, Diff of z, Diff of p
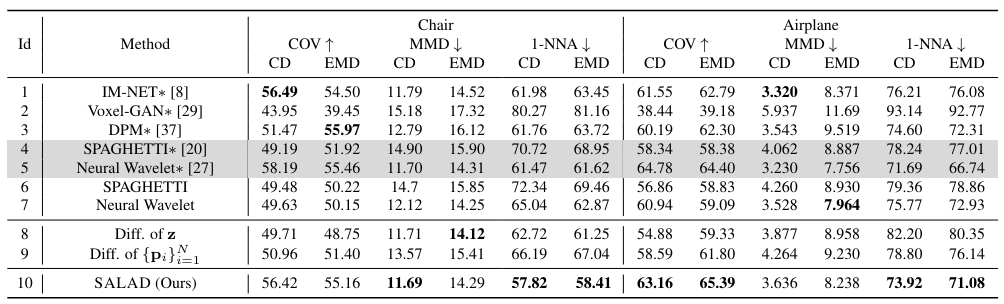
5.1.2. Result
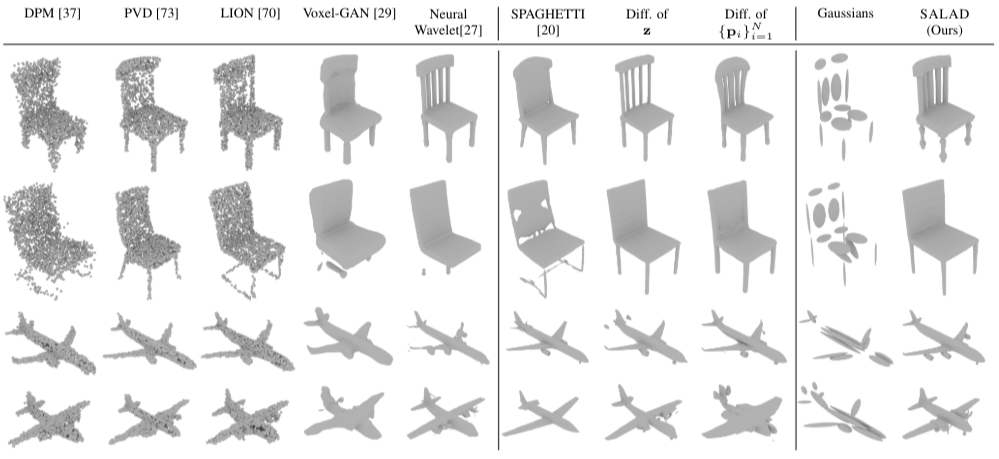
[표 1]에서 볼 수 있듯이, SALAD가 전체적으로 최적의 성능을 내는 것을 확인할 수 있습니다. 특히 3D 생성 모델 중에서 뛰어난 성능을 자랑하는 Nueral Wavelet보다 더 뛰어난 결과를 보였습니다. Ablation study의 경우, SALAD > Diff. of p > Diff. of z 순서로 높은 성능을 보임을 알 수 있습니다. 이는 Transformer와 cascaded training이 얼마나 중요한 영향을 주는지를 보여줍니다.
5.2. Part Completion
5.2.1. Experiment Setup
Meng이 제시한 guided reverse process를 사용합니다. 재구성하고자 하는 구역을 나타내는 mask 변수 $m \in [0, 1]^d$가 주어져 있을 때, reverse process는 다음과 같이 정의됩니다.
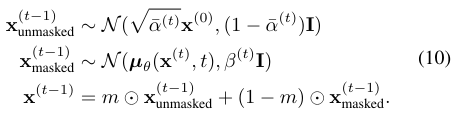
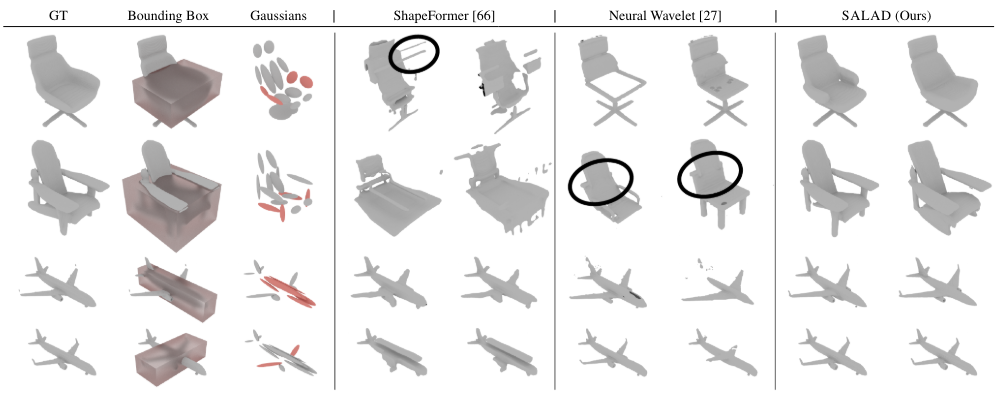
ShapeFormer등과 같은 다른 방식들과 달리, 이는 masking 되지 않은 구역을 온전히 보전할 수 있다는 장점이 있습니다. Mask 값 m의 경우 SALAD와 Neural Wavelet의 구성방식이 다릅니다. SALAD의 경우 원하는 구역에 해당하는 (e, s) 짝을 선택하기만 하면 되지만, Neural Wavelet은 voxel 방식을 사용하기 때문에 axis-aligned bounding box(aabb)로 구역을 정해줘야 합니다. 이런 경우 우리가 원하는 구역보다 더 큰 구역이 선택될 수 있으니 정확히 원하는 결과를 기대하기 어렵습니다.
- 평가 표본 : 무작위로 선택한 100개 표본에서 무작위 부위에 대해 5가지 버전의 채우기를 진행합니다.
- 평가 지표 : reverse-MMD, Reconstruction loss, FPD
- 주요 대조군 : ShapeFormer, Nueral Wavelet
5.2.2. Results
SALAD가 다른 baseline 모델들보다 더 뛰어난 성능을 보이는데, 특히 모양이 얼마나 그럴듯하게 갖추어졌는지를 나타내는 FPD 지표가 크게 차이나는 것을 볼 수 있습니다.
정성적인 분석을 살펴보면, ShapeFormer의 경우 bounding box에서 벗어나는 부산물이 추가로 만들어집니다(1열). Neural Wavelet은 bounding box로 인해 선택되었던 의자 바깥쪽 부분까지 생성된 것을 볼 수 있습니다(2열). 반면, SALAD는 bounding box를 사용하지 않아 튀는 값 없이 정상적으로 의자가 생성되었습니다.

5.3. Part Mixing and Refinement
SALAD는 extrinsic & intrinsic vector를 조정함으로서 서로다른 두 물체의 융합 과정도 나타낼 수 있습니다.
- 평가 표본 : 무작위 100가지의 짝을 선별한 뒤, semantic map을 서로 교환하여 물체를 합쳤습니다.
- 평가 지표 : COV, MMD, 1-NNA
- 주요 대조군 : SPAGHETTI
[표 3]에서 볼 수 있듯이, SALAD는 융합과정에서 baseline 모델인 SPAGHETTI보다 더 뛰어난 성능을 보여주었습니다.
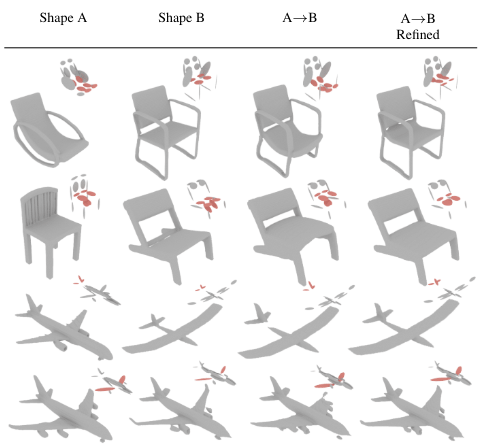
[그림 7]은 SALAD에서의 정성적 결과를 보여줍니다. 첫 융합 결과에서는 끊어지거나(3, 4열) 비틀림(2열) 등의 왜곡된 부분이 보이기도 하지만, refinement 과정을 거친 후의 결과물은 자연스럽게 나오는 것을 볼 수 있습니다.

5.4. Text-Guided Shape Generation
SALAD는 더 나아가 text 기반의 조건부 생성도 할 수 있습니다. 학습에는 text-shape 데이터셋인 ShapeGlot을 사용했습니다. 평가지표 중 하나인 NEP는 input text가 있을 때 주어진 shape들을 올바르게 분류할 수 있는 정도를 나타내는 수치인데, AutoSDF에서 공식적으로 neural evaluator를 배포하지 않았기 때문에 대신 PartGlot의 evaluator를 사용했습니다.
- 평가 지표 : CLIP-Similarity-Score(CLIP-S), Neural-Evaluator-Preference(NEP), Frechet Point Cloud Distance(FPD)
- 주요 대조군 : AutoSDF
결과는 [표 4]에서 보듯이, SALAD가 생성한 모양이 다른 모델보다 더 점수가 높은 것을 알 수 있습니다.


5.5. Text-Guided Part Completion
Text-driven completion의 경우 전체적인 모양은 extrinsic vector $e_i$ 로부터, 그리고 구현해야 하는 semantic parts는 텍스트로부터 가져오는 모델인 GAUSSGLOT을 만들어 수행했습니다.

6. Conclusion
본 연구에서는 part-level implicit representaion을 위한 cascaded 3D Diffusion model인 SALAD를 소개했습니다. SALAD의 핵심은 특정한 bounding region 없이 부분을 선택할 수 있는 disentanglement를 구현했다는 것입니다. SALAD는 다른 3D 생성 모델과 비교해 더 좋은 성능을 보여줬으며, 부분 수정 / 부분 혼합 / 텍스트 기반 생성 등 다양한 종류의 작업 또한 할 수 있음을 보여주었습니다.