[review] DiffusionRig: Learning Personalized Priors for Facial Appearance Editing
2023 CVPR에 투고된 논문입니다. 본문과 코드는 아래 github페이지에서 확인할 수 있습니다.
https://diffusionrig.github.io/
DiffusionRig: Learning Personalized Priors for Facial Appearance Editing
Abstract We address the problem of learning person-specific facial priors from a small number (e.g., 20) of portrait photos of the same person. This enables us to edit this specific person's facial appearance, such as expression and lighting, while preserv
diffusionrig.github.io
1. Introduction

본 논문에서는 대상의 특징을 보존하면서 광원, 표정 등을 변화 시키는 facial expression & manipulation 작업을 다룹니다. 기존의 방법은 대부분 zero-shot learning으로, 큰 데이터셋으로 학습한 후 데이터셋에 없는 완전히 새로운 대상을 이용해 모델을 시험하는 방식을 사용합니다. 이 방식은 시험 대상의 high frequency를 잘 반영하지 못한다는 문제점이 있습니다. 이를 해결하기 위해 본 논문에서는 두 단계로 이루어진 새로운 학습 pipline을 제시합니다. 1단계에서는 큰 데이터셋으로부터 generic facial prior를 학습하고, 2단계에서는 20장 내외의 작은 데이터셋으로부터 personalized prior를 학습시킵니다.
얼굴의 외형을 수정하는 과정에는 기성 모델인 DECA를 사용합니다. DECA는 3D face estimator 모델 중 하나로, 이미지로부터 광원, 표정, 자세 등을 나타내는 3d face model을 추출합니다. 이 3d face model을 바로 이미지로 변환하면 실제 사진과는 다른 조금 어색한 이미지가 생성되는데, 이는 1) high-frequency detail을 놓치고 2) lambertian reflectance와 lighting이 부족하며 3) 3DMM(3D Morphable Model)이 모든 외형을 구현할 수는 없기 때문입니다. 하지만 이 논문에서는 이 3d face model을 바로 사용하지 않고, face rigging의 용도로 사용하게 됩니다.
DiffusionRig는 다음과 같은 순서대로 작동합니다. 먼저 1) DECA를 이용해 초상화에서 physical properties(3DMM)을 추출하고, 2) 3DMM을 기반으로 physical buffer를 생성합니다. 마지막으로 3) Diffusion model을 사용해서 이미지를 생성하고, 대상 인물에 대한 고유 특징을 잡기 위해 4) 작은 데이터셋을 사용한 finetuning을 진행합니다. 추가로, 머리카락이나 안경과 같이 3DMM으로는 나타낼 수 없는 인물의 특징은 encoder를 통해 계산한 latent code를 이용합니다.
2. Related works
- generative model
- 3D morphable face model(3DMM)
- personalized prior
3. Preliminaries

3.1. 3D Morphable Face Models
3D Morphable Face Model(3DMM)은 머리 구도, 얼굴의 기하학적 특징, 표정 등을 compact latent space에서 나타내는 모델입니다. 본 논문에서는 3DMM의 한 종류인 FLAME을 사용합니다. FLAME은 기하학적 특징은 잘 나타낼 수 있지만, 대신 자세한 외형(빛 반사 등)는 잘 보여주지 못하는데, 이를 보완하기 위해 Lambertian reflectance와 spherical harmonics(SH) lighting를 사용한다고 합니다. DECA는 이 반사율, SH lighting, FLAME 매개변수들을 기반으로 리깅을 조절할 수 있습니다.
3.2. DDPM
4. Method
각 대상별 특징을 잘 맞추기 위해서 DiffusionRig는 1) 서로 다른 외형 조건에서 이미지를 생성하고 2) 각 개인의 prior를 학습해 그 고유한 특징이 유지되도록 합니다. 이를 위해서 DiffusionRig는 두 단계의 학습을 진행합니다. 첫 번째 단계에서 모델은 보편적인 얼굴에 대한 특징을 학습하고, 두 번째 단계에서 개인의 얼굴 사진을 학습해 그 고유 특징을 잡아냅니다.

4.1. Learning Generic Face Priors
DECA가 가져오는 매개변수들은 크게 네 가지가 있습니다.
- FLAME parameters : shape β / expression ψ / pose θ
- albedo α
- camera c
- lighting I
이들 매개변수를 Lambertian reflectance를 통해 세 가지 physical buffer로 변환할 수 있습니다.
- Surface normals
- Albedo
- Lambertian rendering
위 physical buffer들을 수정하면 생성한 이미지를 disentangled 상태로 리깅할 수 있습니다.
Physical buffer로 표현되지 않는 기타 조건들 (머리카락, 모자, 안경, 배경 등)은 미리 학습된 diffusion model의 global latent code를 사용합니다. 따라서 DiffusionRig 모델은 다음과 같이 나타낼 수 있습니다.

- $x_t$ : noisy image
- $z$ : physical buffers
- $x_0$ : original image
- $\epsilon_t$ : predicted noise
- $f_\theta$ : denoising model
- $\phi_ \theta $ : global latent encoder
이론상으로 global latent가 (이 모델에서는 physical buffer로 조정하는)local geometry도 수정할 수는 있습니다. 하지만 본 연구에서는 모델이 physical buffer를 이용하는 방향으로 학습하는 것을 확인했습니다. 이는 physical buffer 방식이 pixel-aligned여서 사용하기 더 편하기 때문이라고 합니다.
4.2. Learning Personalized Priors
첫 단계 학습을 마치면, 얼굴의 특징을 보존하기 위한 두 번째 단계 finetuning을 진행할 수 있습니다. 이 finetuning 단계는 20장 내외의 데이터셋으로 denoising model이 대상 인물의 고유한 특징을 학습합니다. 이 때 이전 단계에서 학습한 global encoder는 고정합니다. 이러한 방식을 사용하면 GAN 모델과 비교하여 더 간단하고 효과적인 성능을 보인다고 합니다. 사진에서 DECA parameters를 추출하는 것은 첫 번째 단계와 동일하지만, 이번에는 각 사진에서 추출한 모든 FLAME parameter의 평균값을 사용합니다. DECA의 결과값은 극단적인 구도나 표정에 대해서는 민감하게 변하기 때문입니다.
4.3. Model Architecture
DiffusionRig에서 학습시킬 수 있는 부분은 크게 두 가지 입니다. 첫 번째는 denoising model $f_{\theta}$로, 기존의 ADM 모델에서 계산 비용을 낮추고 global latent code를 더 추가한 버전이라고 합니다. 두 번째는 global latent encoder $\phi_{\theta}$로, ResNet-18을 사용합니다.
Loss function은 P2 weight loss를 사용합니다. P2 weight loss는 예측한 noise와 ground-truth noise의 차이를 계산하며, [식 2]와 같이 정의됩니다. P2 weight loss는 constant loss weight와 비교해서 학습 속도를 높이고 이미지를 더 잘 생성한다고 합니다. ($\lambda_t$는 hyperparameter)
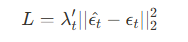
4.4. Implementation Details
- frist stage (15hours, 8 A100 GPUs)
- dataset : FFHQ
- optimizer : Adam
- lr : 10^-4
- iteration : 50,000
- batch size : 256
- second stage (30min, one V100 GPU)
- 20 images
- iteration : 5000
- batch size : 4
- lr : 10^-5
5. Experiments
5.1. Rigging Appearance With Physical Buffers
개인화된 모델을 사용하여 외형을 리깅하는 작업을 진행합니다. 리깅은 physical buffer를 수정하는 방식으로 진행되는데, 이 수정 방법에는 크게 세 가지가 있습니다.
- Relighting 수정 : Spherical Harmonics (SH) 매개변수를 수정합니다. 이를 통해 Lambertian rendering을 만들 수 있습니다.
- Expression 수정 : FLAME 매개변수(pose vector θ의 마지막 세 개 매개변수)를 수정합니다. 인물의 표정과 하관의 회전률(jaw rotation)을 조정할 수 있습니다.
- Pose 수정 : head rotation 매개변수(pose vector θ의 처음 세 개 매개변수)를 수정합니다.
[그림 4]는 유명인 2명과 일반인 1명을 대상으로 한 256 * 256 크기의 이미지 리깅 결과를 보여줍니다. GIF는 expression과 pose의 리깅이 가능하지만, 개인의 특징을 잘 보존하지 못하는 것을 볼 수 있습니다. MyStyle의 경우 특징을 잘 보존하면서 생성하지만, 수정을 위해 직관적이지 않은 latent space에서 특정 값을 찾아야 한다는 문제가 있습니다. 또한, 적은 이미지로 fintune할 때 불필요한 artifacts들이 생성되는 것을 확인할 수 있습니다. 반면 DiffusionRig는 물리적인 접근으로 외형을 수정할 수 있으며, 동시에 인물의 특징을 잘 보존할 수 있습니다.

5.2. Rigging Appearance With Global Latent Code
Global latent code를 이용해서 physical buffer로 나타낼 수 없는 환경 요소(머리카락, 배경 등)를 잘 구현할 수 있는지 확인합니다. [그림 5]는 서로 다른 physical buffer와 global latent coded가 조합된 결과를 보여줍니다. 각 열은 서로 다른 global latent code를 나타내고, 행은 서로 다른 physical buffer를 나타냅니다. 결과를 통해 DiffusionRig는 physical buffer와 global lantent code가 가지는 속성들이 잘 disentangled 되어 있음을 확인할 수 있습니다.

5.3. Identity Transfer With Learned Priors
Personalized diffusion model의 가중치로 어떤 정보가 학습되는지 확인합니다. [그림 6]은 physical buffer와 latent code를 유지한 채 personalized model만 교체했을 때의 결과를 보여줍니다. 각 행은 서로 다른 physical buffer를 가지고, 각 열은 서로 다른 personalized model을 가집니다.

5.4. Baseline Comparisons & Evaluation Metrics
DiffusionRig의 성능은 크게 세 가지 측면에서 평가되었습니다.
5.4.1. DECA Re-Inference Error
리깅의 품질을 나타냅니다. Re-inferred spherical harmonics의 RMSE를 계산해서 구할 수 있으며, 자세한 설정은 GIF 연구에서 수행한 평가 내용[1]을 따릅니다. Ablation study로 physical buffer 대신 vector conditon과 feature condition을 사용해보기도 했습니다(5.5절).

5.4.2. Face Re-Identification Error
외형을 수정했던 결과물을 face re-identification network[2]를 통해 원본사진과 동일한 인물로 추론할 수 있는지를 확인합니다. MyStyle과 DiffusionRig 모두 400개의 수정된 이미지들에 대해 특징을 잘 보존하는 것으로 확인되었습니다.

5.4.3. User Study
DiffusionRig와 MyStyle의 보다 자세한 비교를 위해 user study를 진행했습니다. User study는 Amazon Mechanical Turk를 이용하였으며, original image와 generated image를 두고 두 인물이 같은지 평가를 요구하였습니다. 결과는 [표 2]에 함께 제시되어 있습니다.
5.5. Ablation Study
Personalized prior의 fintuning과 모델 condition 조정을 위해 ablation study가 진행되었습니다.
5.5.1. No Personalized Priors
먼저 personalized priors가 없이 Stage1만 학습했을 때 DiffusionRig의 성능을 확인했습니다. 그 결과 [그림 2]에서 볼 수 있듯이, 인물의 특징을 보존하면서 수정하는 것이 불가능했습니다.
5.5.2. Number of Images
Stage 2에서 학습 이미지의 개수가 성능에 어떤 영향을 미치는지 확인했습니다. 각 1, 5, 10, 20개의 데이터셋에 대해 stage 2 학습을 하고 각각에 대해 relighting, expression, pose change를 평가했습니다. 그 결과 1, 5, 10개 데이터셋의 경우 20개 데이터셋 보다 안 좋은 결과를 보여주었습니다. [그림 7]은 relighting과 pose에 대해 비교한 결과입니다.

5.5.3. Different Forms of Conditions
기존에 사용했던 pixel-aligned physical buffer대신 다른 값을 사용했을 때의 결과를 비교합니다. 비교 대상은 두 가지로, vector condition은 DECA의 결과값 parameter를 physical buffer변환 없이 직접 사용합니다. 이 경우 pixel-aligned buffer를 사용하지 않은 236차원 벡터를 사용합니다. Feature condition은 physical buffer를 원본 image와 그대로 결합(concatenation)한 뒤, 합친 값을 encoder에 넣어서 계산한 global latent code를 사용합니다. 이 경우 non-spatial feature 조건으로 사용합니다. 실험 결과, 두 가지 모두 의도하는 physical guidance를 따르지 않음을 확인했습니다.

6. Limitations & Conclusion
DiffusionRig는 SotA 성능을 보여주었습니다. 하지만 몇가지 한계점도 존재하는데, 우선 fintune을 위해 추가적으로 작은 데이터셋을 필요로 하다는 단점이 있습니다. 추가로, 극적인 head pose 변화에 대해 기존의 배경을 잘 생성하지 못한다는 문제가 있습니다. 하지만 이는 inpainting의 문제로, 본 연구의 범위가 아님을 밝힙니다.
또한 DiffusionRig는 DECA를 기반으로 하므로, DECA가 가지는 한계점(extreme expression의 예측에 취약, 피부 톤과 관련된 lighting 문제 등)을 같이 가지고 갑니다.
Reference
[1] Partha Ghosh, Pravir Singh Gupta, Roy Uziel, Anurag Ranjan, Michael J Black, and Timo Bolkart. Gif: Generative interpretable faces. In 2020 International Conference on 3D Vision (3DV), pages 868–878. IEEE, 2020.
[2] Davis E. King. Dlib-ml: A machine learning toolkit. Journal of Machine Learning Research, 10:1755–1758, 2009.